
【Siggraph 2014】Next generation post-processing in call of duty advanced warfare
COD在Siggraph 2014上分享过他们在后处理方面的一些工作要点,其中的一些内容对今天的游戏开发依然有不小的帮助,这里将其中的一些要点分享出来。
照例,先来对全文的关键信息做一个简短的总结:
- 本文对COD advanced warfare中的后处理相关各项技术细节做了介绍,包括运动模糊、DOF、SSS以及Bloom/Veil,同时还介绍了其阴影采样点计算的优化要点
- 运动模糊跟DOF都采用了scatter-as-you-gather方法,即在计算当前像素结果时,从周边像素处获取其颜色并按照一定的原理做加权混合,不同的时候DOF是周边所有像素,而运动模糊则是考虑运动路径上对当前像素有覆盖的像素,其中有如下几个要点
- 通过分tile的方式来找到最大运动速度,从而获取到运动模糊的贡献像素的所在范围
- 为了避免tile划分影响结果的准确性,这里还需要对tile做一个3x3的最大值滤波
- DOF也有类似机制,不同的是DOF针对的不是速度,而是CoC半径
- 运动模糊的权重理论上应该是运动路径上每个像素都按照同样的权重来计算贡献,不过这个在部分情况下会导致沿着轮廓的跳变(inner blur跟outer blur),这里针对这种情况调整了权重计算逻辑,在硬边位置特殊处理
- 运动模糊的时候,前景跟背景数据会根据计算得到的一个alpha做混合,同时,对于看不见的背景数据,通过将运动方向前后两侧数据的权重做镜像处理来实现平滑。
- 在模糊的时候,由于采样数目较少(性能考虑),模糊结果往往会存在瑕疵,这里通过对采样结果做噪声、dither等处理来实现平滑
- 最后,运动模糊还设计了fast path来避免全屏幕的重度计算
- 通过分tile的方式来找到最大运动速度,从而获取到运动模糊的贡献像素的所在范围
- DOF这边也做了一系列的优化,包括
- 单独的presort pass
- 通过remapping对前景、背景混合的alpha进行处理,避免背景区域的颜色漏到前景区域
- 为避免remapping本身的副作用,这里还设计了一套策略,在不同的位置使用不同的remapping强度
- 通过预滤波(Karis平均值算法,滤除高光抖动)+中值滤波(效率高,不影响高光)来降低采样不足导致的噪声
- 针对阴影多点采样,提出了一个Interleaved Gradient Noise方法,通过仔细设计的螺旋转采样点,使得多帧(采用不同旋转角度)采样点的位置不重叠,从而实现数据的稳定复用以降低噪声
- 该方法适用于所有需要多点采样的场合,比如SSAO
- 次表面散射是基于Jimenez 2013的separable SSS方案改造而来,通过双pass(水平+垂直)的模糊实现近景模糊跟远景模糊数据的获取,之后按照一定的方式完成混合
- 这里通过importance sampling来降低采样点数目
- 同时通过一定的策略跳过了depth difference的需要
- Bloom的计算也做了较多的优化
- 针对下采样跟上采样采用不同的滤波方式
- 下采样mip 0到mip 1采用了Karis平均算法滤除了高光锯齿
- 上采样通过tent filter实现对高斯模糊的逼近



分享的技术小哥认为,对于写实风格的作品而言,后处理是游戏效果是否能逼近影视效果的关键。

后处理工作的优化思路总结下来有上述几个要点。

大纲如上,会从三方面进行介绍:
- 基本概念
- 面临问题
- 对应方案

运动模糊在快速移动的游戏中,会有非常重要的作用。

参考[3]:
真实世界中,自然光在感光材料上产生光化学作用,形成潜影的过程叫做曝光。
在这个过程中,如果拍摄对象发生了相对相机的移动,就会导致恒定输入的持续曝光变成非恒定输入的曝光叠加,最终体现为拍摄物体的模糊,也就是常说的运动模糊
同时,人类肉眼的视觉暂留现象,同样也是因为感光细胞中感光色素形成的延迟形成的
缺少动态模糊的画面,反而会丧失运动感,使观众失去焦点并从直觉上感觉画面断断续续而不自然
运动模糊是提升效果真实感的重要手段,常见的运动模糊有三类:线性、旋转以及缩放(径向)。而常见的模拟方案有如下几种[3]:
- Accumulation Buffer:将运动的物体按照运动方向做多次渲染,之后按照一定的权重累加之后,再叠加到静态背景上
- Velocity Buffer:基于屏幕空间每个像素的速度向量,做一个向前与向后的颜色扩散,以模拟该像素经过路径上的染色行为
- 按照曝光的理论,运动模糊表现为前后两部分的虚化,解释如下:
- 前端的虚化在于有限的曝光时间下,动态物件在前端位置的停留时间较短,因此需要混合一部分原有的背景数据
- 后端的虚化在于,动态物件只有前面几帧的数据残留下来,后续多帧此处区域已经没有动态物件的贡献,同样因此需要叠加背景数据
- 按照曝光的理论,运动模糊表现为前后两部分的虚化,解释如下:
注意:上图中介绍的第二种Stochastic Rasterization的方案不是上面说的Velocity Buffer的方案,而是通过随机噪点的方式来模拟的方案,参考[6]

Accumulation Buffer的方案成本过高,一般没人考虑,本文介绍的方案主要是基于velocity buffer的。
需要注意的是,屏幕空间的方案(后处理),由于并不是所有信息都具备,因此通常不会十分的精确。
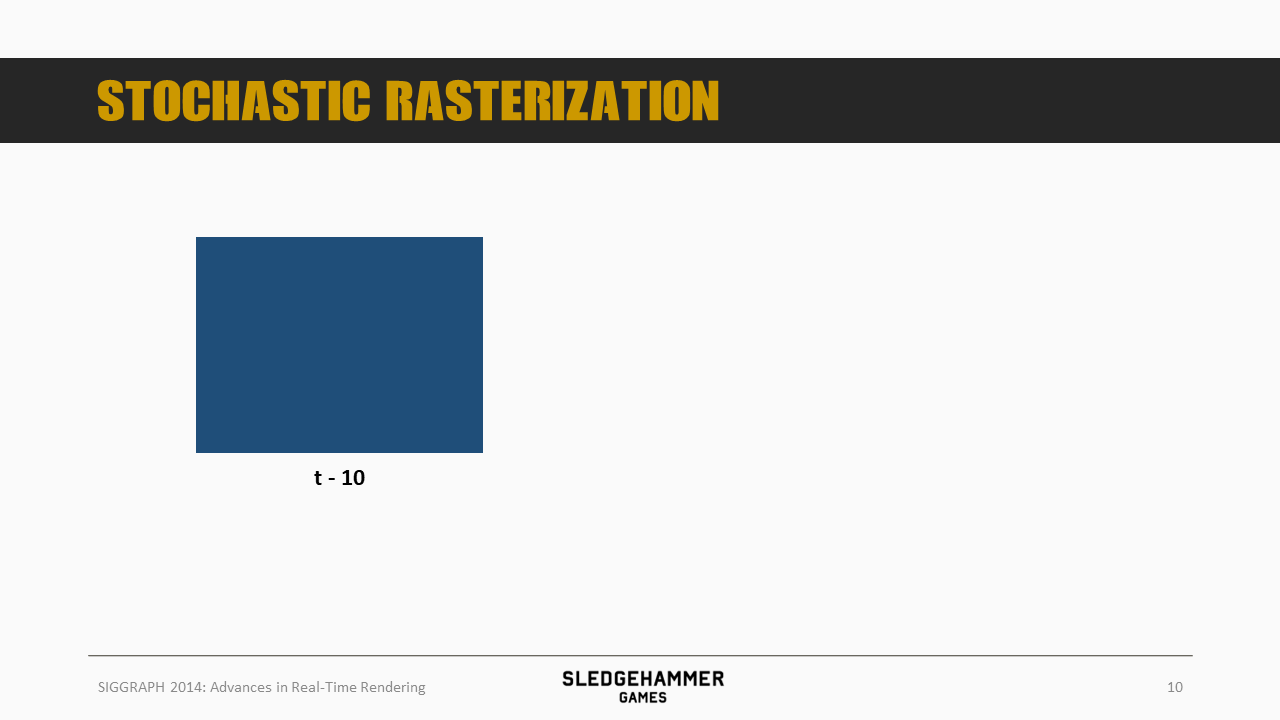
虽然最终用的不是随机光栅化方案,但是这个方案对本文要介绍的Motion Blur以及DOF方案提供了较多的启发,因此还是把实现思路做一个简单的同步。
这里有一个移动的矩形,处于t-10时刻
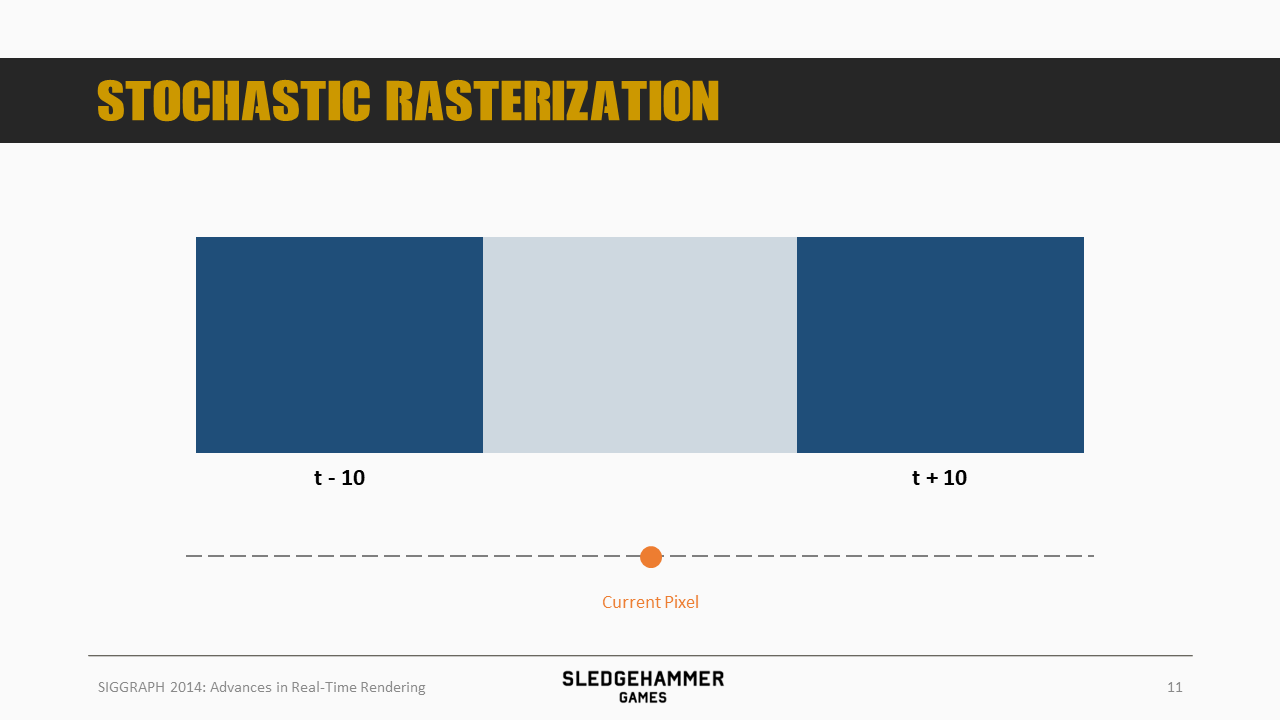
在t+10时刻移动到了一个新的位置,而随机光栅化方案则是对该矩形的像素做一个随机处理,基于随机结果将之摆放到以前后两个位置为范围的中间某个位置上,可以简单记为NewPos = LastFramePos + (CurFramePos - LastFramePos) * Random
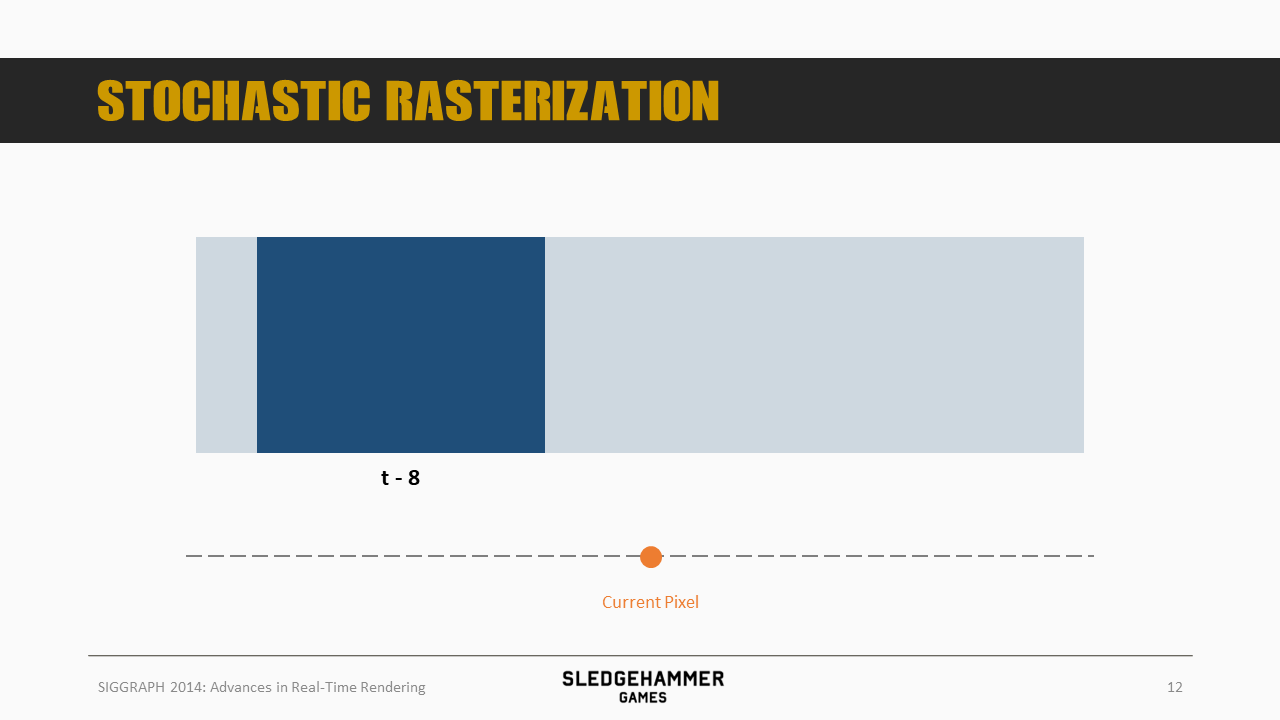
比如,这个物件的某个像素会出现在t-8的位置
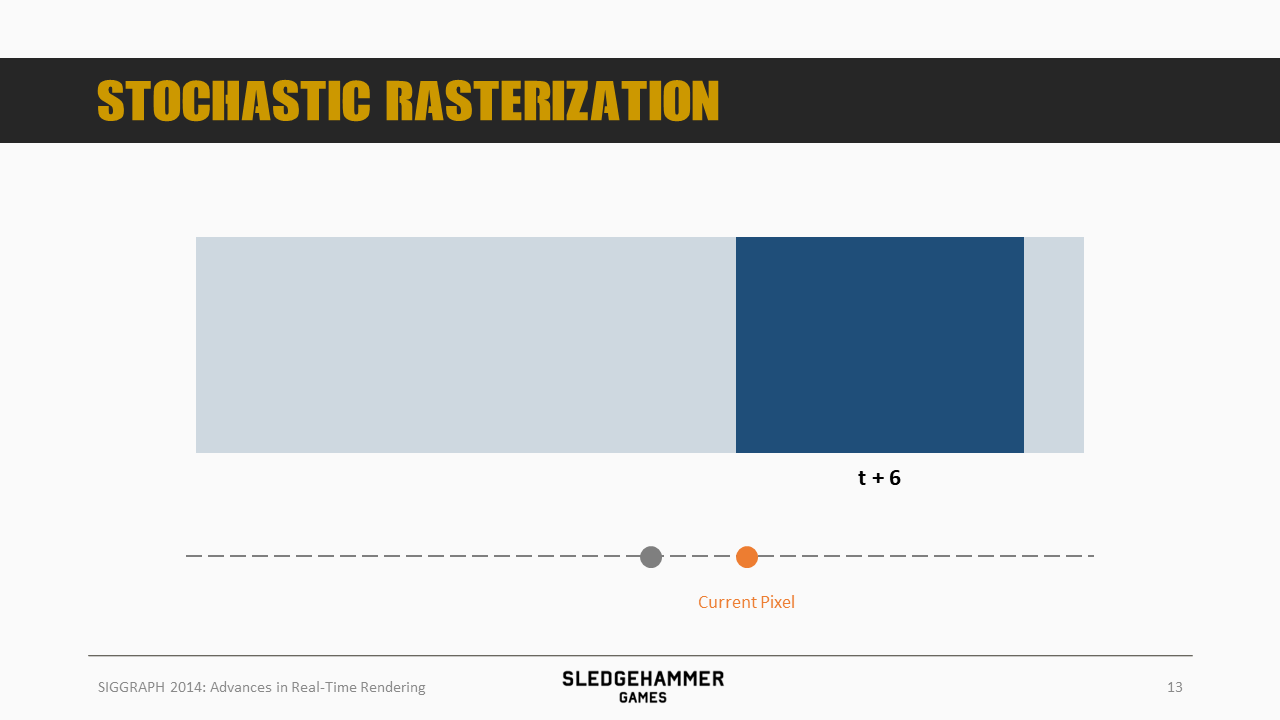
另一个像素则出现在t+6位置
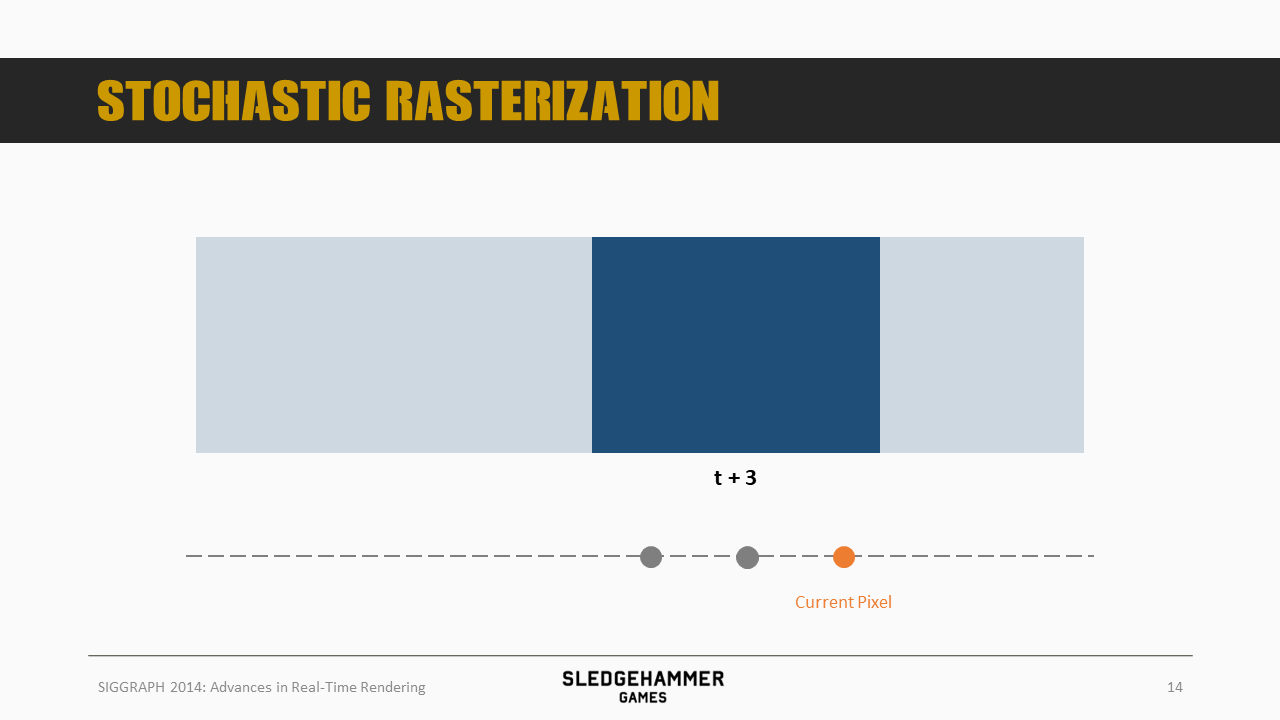
再一个出现在t+3位置。
不过这里有个问题,如果矩形上的每个像素都单独做这么一个随机,就会使得效果噪声过强

但是如果对于某个像素,我们做多次随机,之后将随机到某个位置的数据累加起来的话,效果就会好起来,即:
- PixelA -> {SampleA0, SampleA1, …, SampleAN} with Random Strategy
- PixelColor = Sum(Samples)/N,这里Samples指的是经过随机后落在当前位置的像素颜色

上述多次随机的过程也可以理解为带有alpha的样本混合,即将一个像素分成多个部分,每个部分分别放到不同的位置

回到最初的输入,我们只有一张color buffer,一张velocity buffer以及一张depth buffer,要怎么实现上述的过程呢?

问题就转化为了,如何将运动(这里说的运动,说的是相对于人眼,或者游戏中的相机,对于相对于相机不动的像素,理论上也不需要叠加,下同)的物体沿着对应的方向做一定比例的拉伸,并且将拉伸后的效果按照一定的比例与背景做混合

而我们可以通过:
- 将前景物体做模糊来实现物件的伸缩
- 前景物体指的是相对于相机运动的物体,下同
- 模糊方式有线性模糊、径向模糊等
- 伸缩范围对应于模糊半径,对应于移动速度
- 前景与背景混合的alpha,则可以通过对该物体移动到该位置时的叠加次数(除以总次数)来得到
- 甚至这里可以基于移动速度推导出一个公式,避免alpha贴图的需要
这俩贴图都可以通过scatter-as-you-gather后处理算法计算得到。

先来看下最直观的做法:基础散射(Scatter)算法。
我们的运动模糊可以通过将某个像素沿着其运动的方向不停地扩散来得到
为什么是向前向后扩散,而不是背向运动方向做扩散(表示将过往帧数的数据叠加起来)? 基于上下文的推测,应该是为了解决背景信息获取不到的问题而做的调整,比如一辆车,如果按照单向模糊来做,那车头部分就需要混入被车头所遮挡的背景信息,而基于当前帧的scene color做的模糊,这部分数据是缺失的,怎么办呢?干脆做成双向模糊,将模糊区域从车头移动到车头前面的背景区域,这样就能拿到车头与背景的数据了。

比如前面的点,向前向后两边扩散,就得到了这条线
这种计算思路叫散射算法,在实现层面,则是基于当前点的速度,将之叠加到被其速度所覆盖的周边像素上。
这个算法虽然理解直观,但实现起来比较低效
考虑到GPU的特性,想要将一个像素的数据取出来写入到多个UV位置,有几种做法:
- 分成多个pass实现
- 在单个pass中实现,借助UAV的特性完成
- 通过GS,将单次的全屏后处理,转化为多次(多个triangle)
不论是哪种方式,计算消耗都不低(UAV在吞吐量与读写延迟上都远远不如RT/SRV,30%左右的差异)
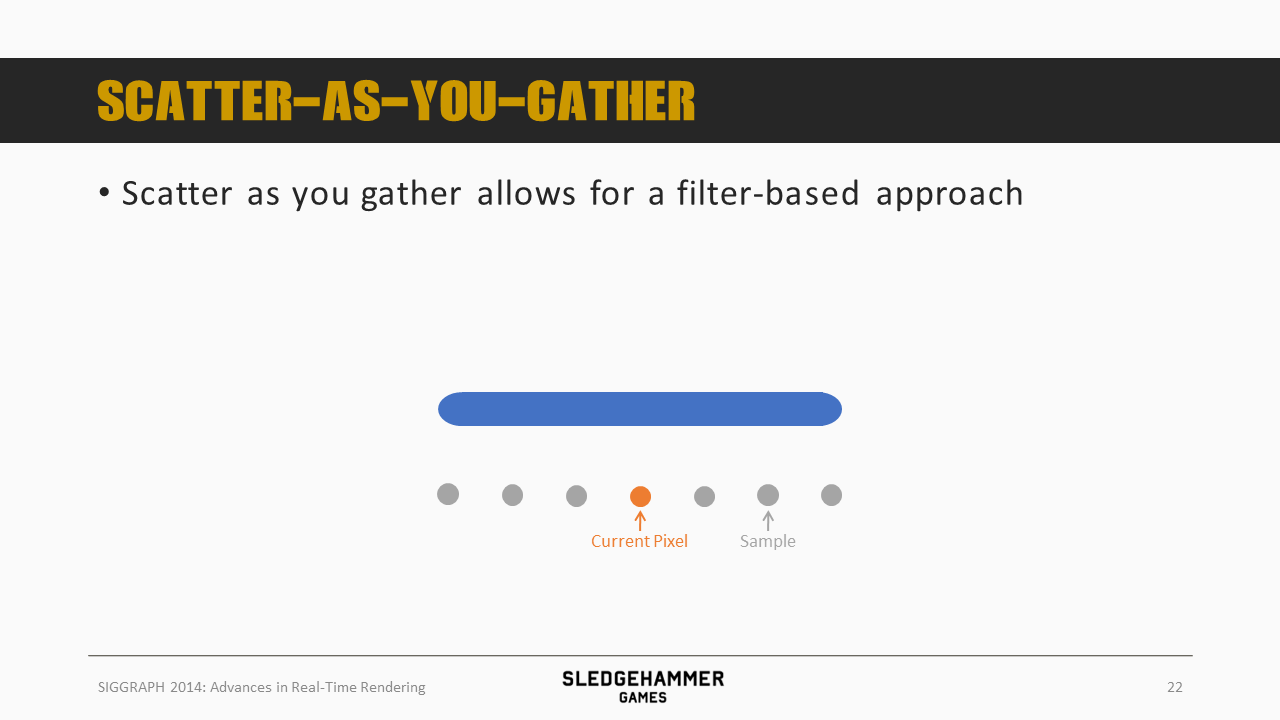
接下来换个角度看看问题,介绍一下前面说到的scatter-as-you-gather(简称Gather)方法:这次我们不再将某个像素沿着其移动的方向做扩散,而是对于每个位置,我们检查其相邻的像素,看看是否会被该像素扩散过来(需要判断速度是否能够覆盖)。
扩散方法其实是将一个像素写入多个位置(需要多个pass),scatter-as-you-gather则是从多个像素读取数据写入一个位置(只需要一个pass)。

scatter-as-you-gather执行起来较为高效,不过会遇到较多的边界情况,总结起来有三个问题需要解决:
- 如何知道当前像素的采样范围(Gather半径),即哪些像素是可能对当前像素产生贡献的,这里会存在一个分歧:
- 如果范围过大,就会导致计算性能的浪费
- 如果范围过小,就会因为部分数据缺失,从而导致效果问题
- 要如何知道哪些像素应该扩散至当前像素,即范围内哪些像素是能够对当前像素产生贡献的
- 这里既需要考虑到像素间的遮挡遮挡关系避免叠加了错误数据,同时还要考虑贡献方的速度,从方向与大小与深度来判断是会产生贡献
- 如何恢复背景数据,即对于被前景物件所遮挡的区域,如何拿到对应的数据
下面对这三个问题分别通过事例来介绍。
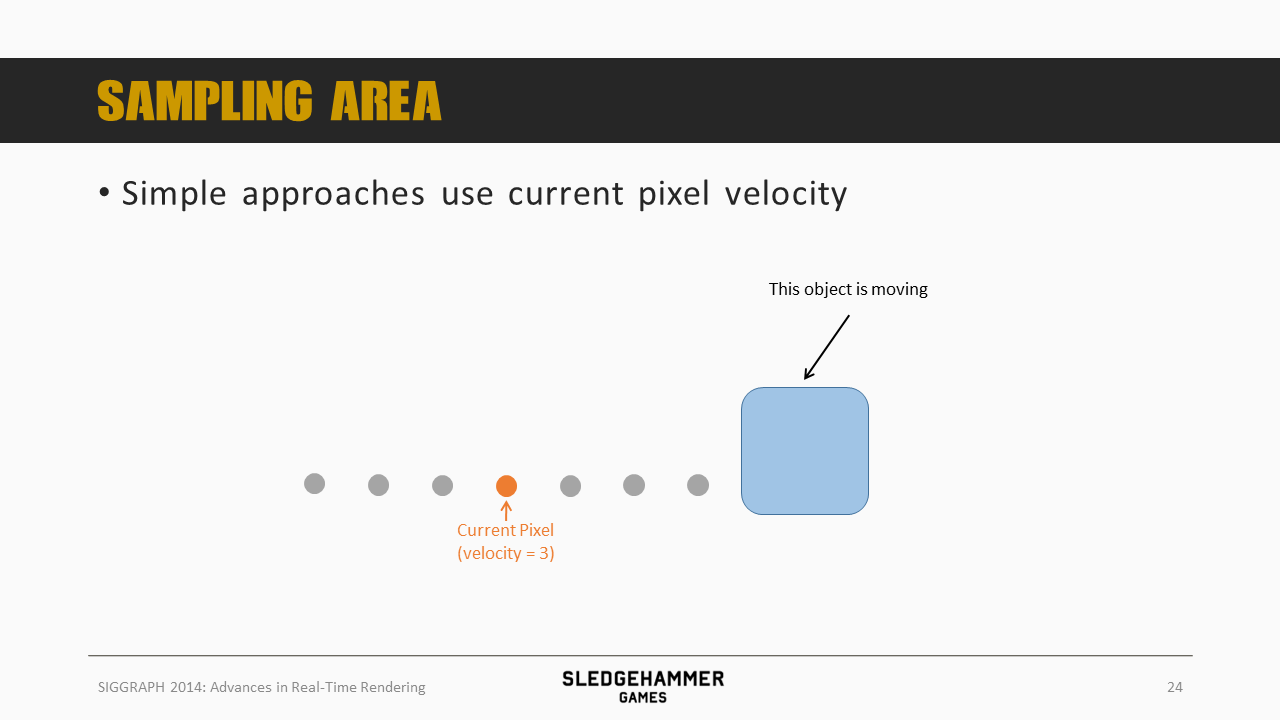
先来看看采样范围的事情,最简单的方法就是基于当前像素的速度来计算,不过这里会有问题。
如上图所示,假设当前像素的速度为3(往右),那么其采样范围就是前后各三个采样点。
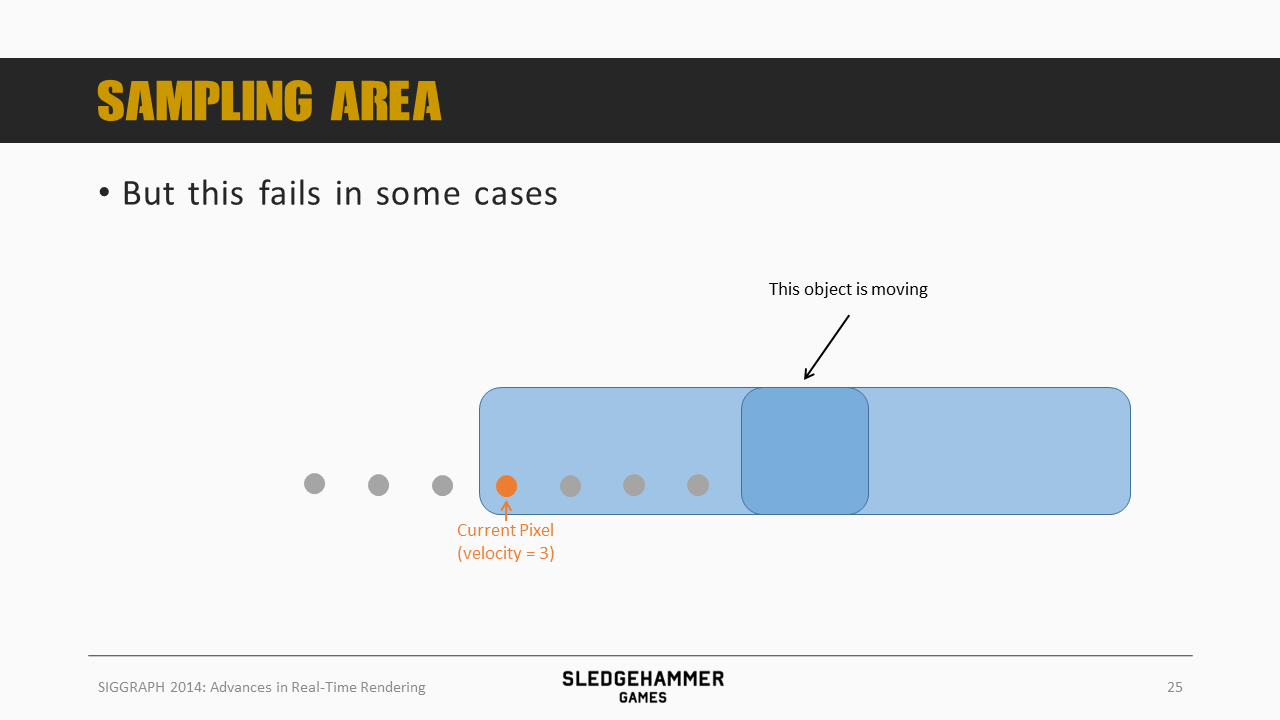
但如果蓝色物体的移动速度高过3,那么从现实中的经验来看,其应该对当前像素产生贡献,但假如按照当前点(橙色)的速度来采样,蓝色box的数据就没有办法进来,导致结果错误。

再来看第二个问题
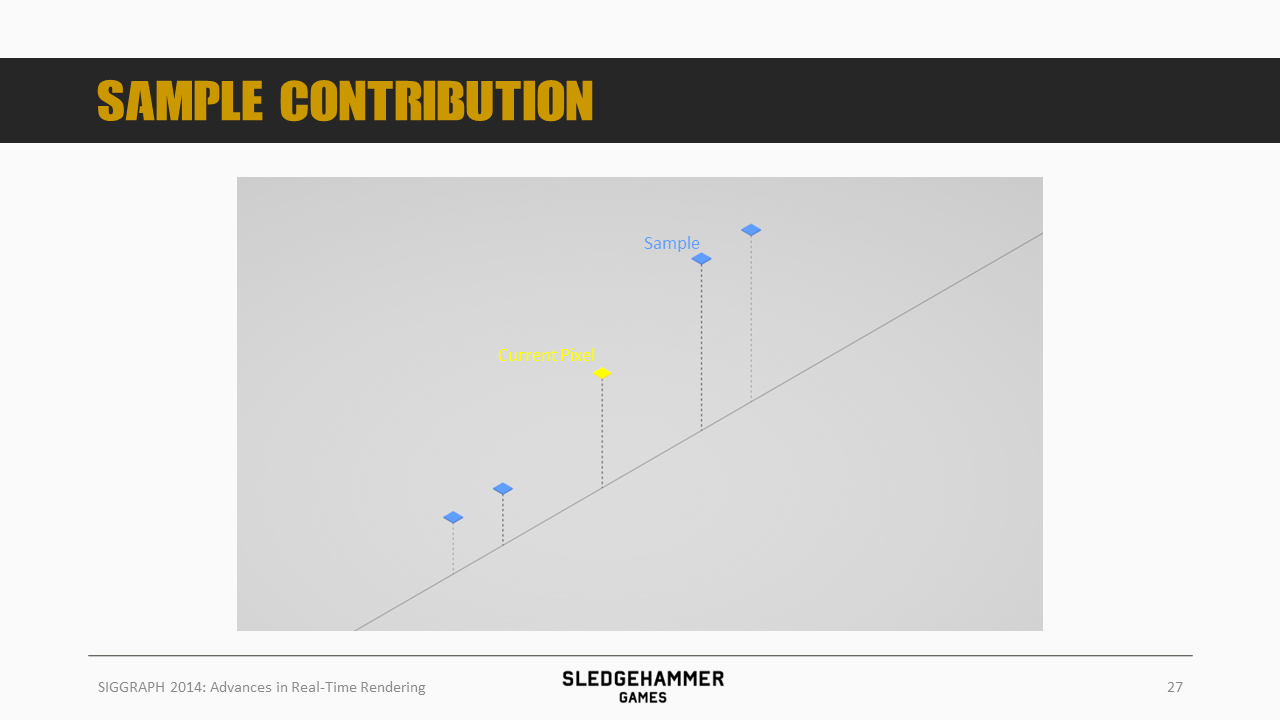
假设我们运动模糊的kernel是5(采样周边5个像素),上图中每个像素的高度代表深度的倒数,即越高表示距离相机越近。
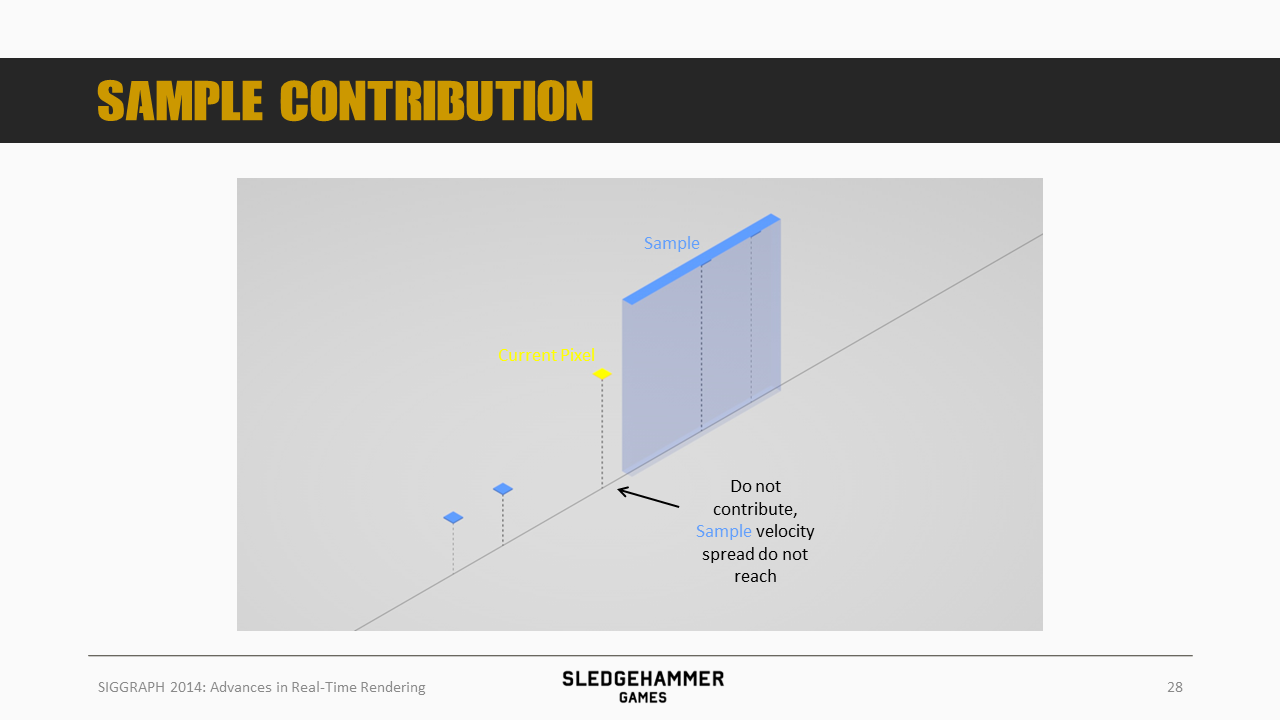
假设当前的像素点为图示黄色采样点,同时,待采样的sample位于右边,其(左右)扩散的范围用蓝色box表示
按照图示情况,因为没有覆盖到黄色像素,所以该sample的颜色就不会叠加到黄色点上。
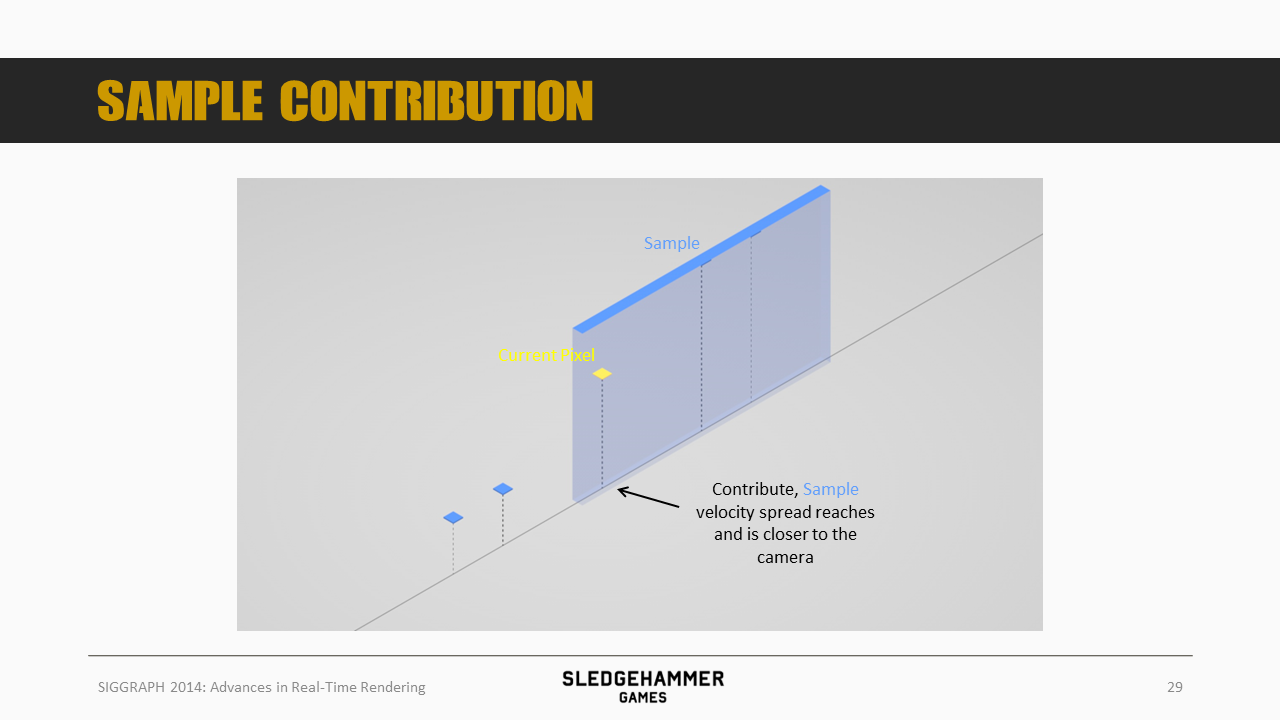
如果蓝色sample的移动速度加快到能够覆盖到黄色像素,此时由于蓝色sample距离相机更近,sample的颜色就会被叠加到黄色点上。
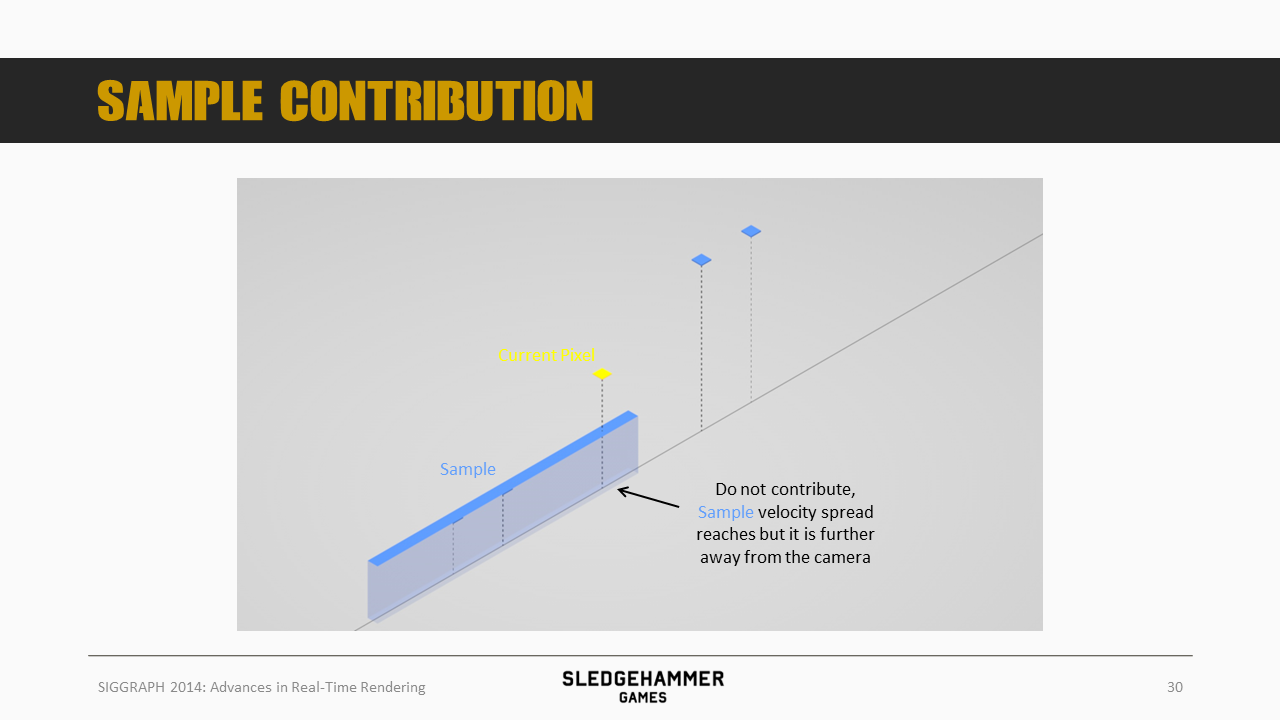
而对于上图这种左侧的蓝色点的情况,虽然速度足够快,能够覆盖到蓝色点,但是由于其距离相机更远,也就是说即使其移动轨迹有与黄色点重合的部分,但重合的部分实际上是被黄色点所遮挡的,因此这个sample的颜色是不应该叠加到黄色点上的。

再来看最后一个问题。
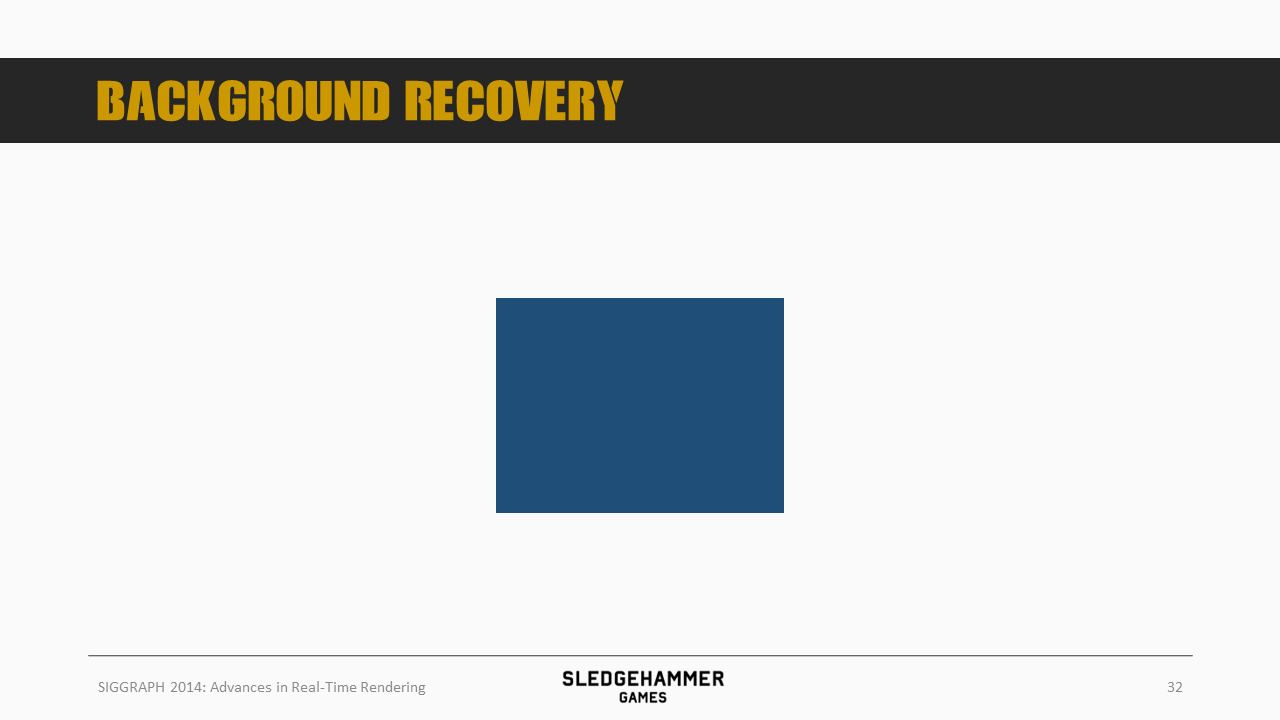
如上图的蓝色box所示,假设这里有个水平移动的物体
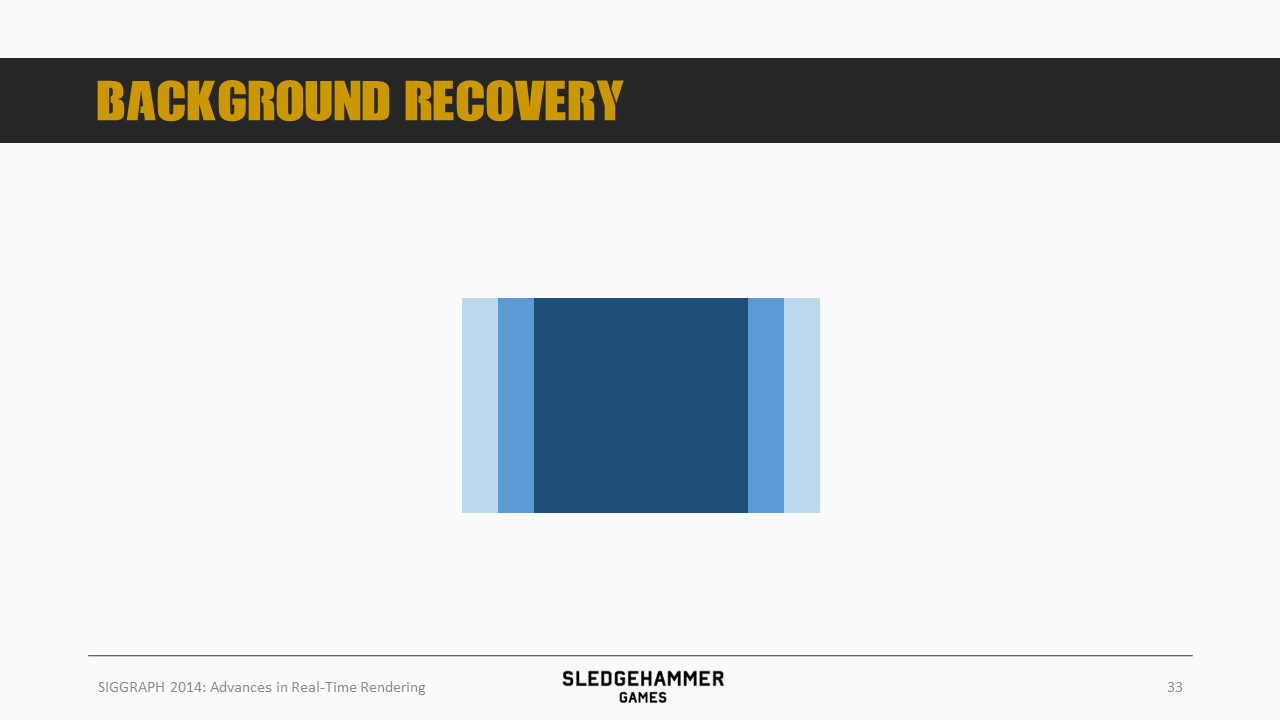
前面介绍了Motion Blur的Accumulation Buffer实现算法,在这种算法下,我们就需要将该物体沿着轨迹渲染多遍,并混合叠加(当然,叠加结果需要除以混合次数)。
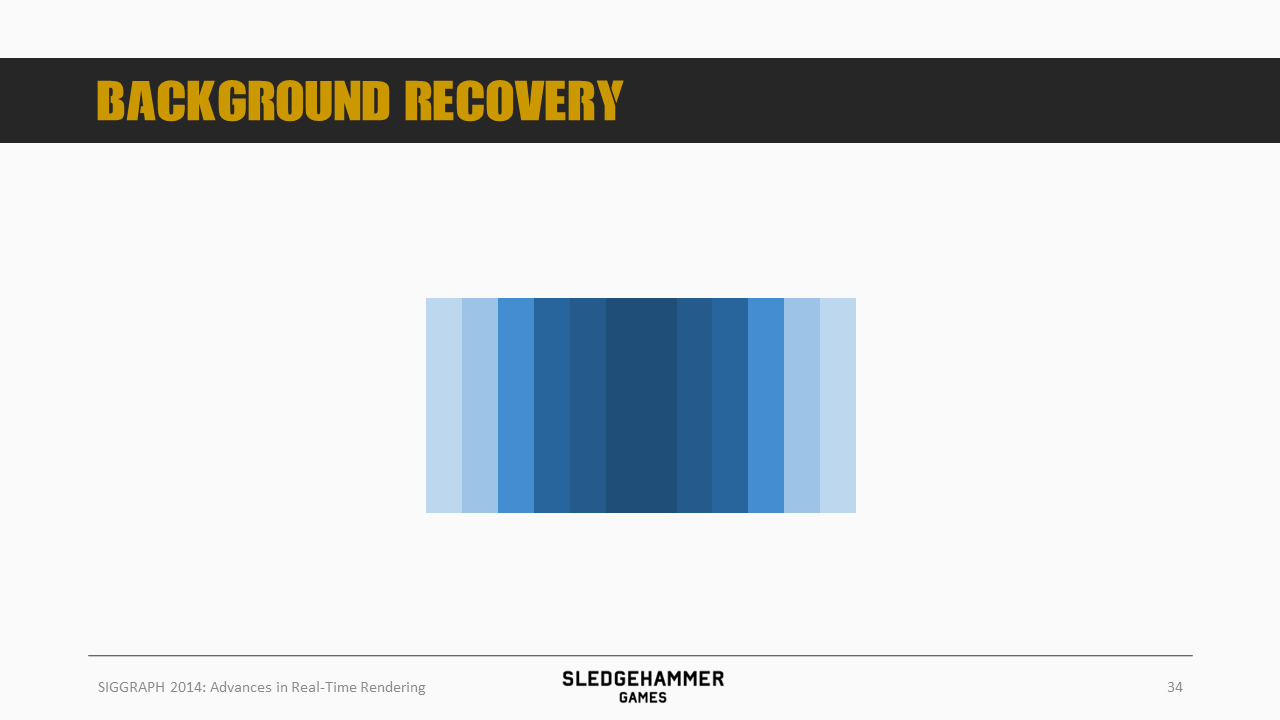
最终的混合结果大致如上图所示(效果跟前面的前后两端虚化的结论是一致的)。
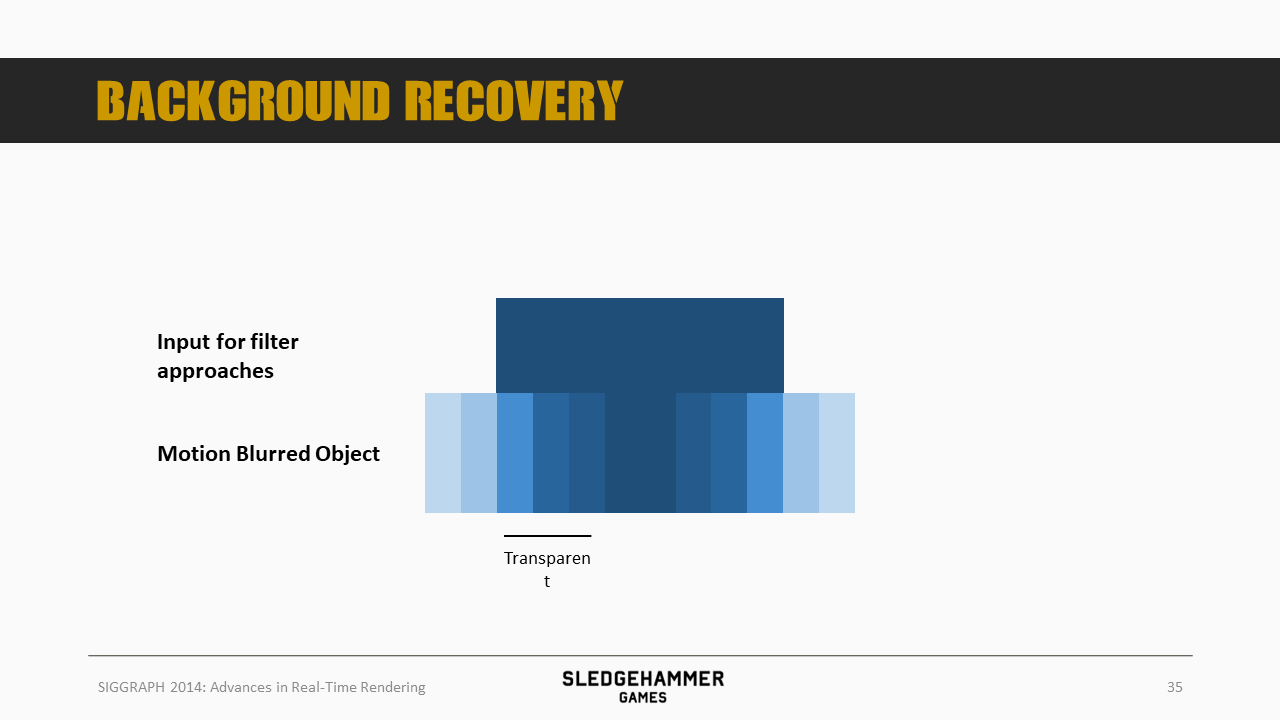
将最终的效果跟我们的原始color buffer输入相比较,我们就会发现,动态物体移动速度方向前后两端部分已经虚化,虚化的部分需要与背景颜色相叠加。
然而,因为所有的模糊都是基于当前帧的color buffer数据完成的,对于前端区域需要叠加背景颜色的情况,由于背景颜色数据是缺失的,因此这里叠加的颜色从哪里取得,就会是一个问题。

下面基于图片做进一步说明

这是运动模糊后的效果,其中红线描边部分是原始角色所覆盖的区域的轮廓线,这里也可以理解为当前帧,角色的外轮廓。
如果将图片放大,我们就会发现,模糊的数据其实是分布在红线的两边的(这个其实还是因为前面说的,需要将当前像素的数据向前向后scatter,但是一直不明白,为什么不是只向后scatter)
而红线内侧的邻近区域,由于在当前帧的scenecolor中是被角色所遮挡的,此时虚化时需要叠加背后的天空数据,而天空数据因为被角色遮挡而无法获得。

针对前面的问题,我们逐一来解答。本文要介绍的方案是基于McGuire的,之后参考了Sousa 2013的vectorization实现逻辑。
据原文作者介绍,McGuire的方案是第一个解决了上述三个问题的方案,本文是在McGuire方案的基础上做了部分改进。

先来看看采样范围的问题,其实我们要解决的是,在一个给定的快门时间内,对当前像素产生贡献的所有像素所在的范围,而这个范围不用很精准,可以稍微保守一点。

这里用的方案跟McGuire的方案一样,即以tile为单位统计各个tile的最大速度。

这里有一个问题,即如果我们直接以tile的最大速度来推算覆盖范围,就有可能出现,A tile的最大速度覆盖不到B Tile,但是B Tile的速度更大,却会覆盖A Tile,从而导致覆盖范围计算结果不准确。
为了解决这个问题,这里还会增加一个额外的pass,即对tile的速度数据,做一个3x3(tiles)的最大值处理,从而保证相邻tile的数据都被考虑到了。

最后基于该速度来推测当前像素采样的范围(计算消耗有点高,移动端可能接受不了)。

再来个直观的展示,这是Blur之前的贴图

如果以当前像素的速度来计算覆盖范围,得到的模糊效果如图所示

而按照前面tile方法的最大速度来计算覆盖范围,得到的效果是这样的,注意看模糊区域过渡效果,这种方案过渡明显更为平滑(而前面的方案则有硬边)。

再来看第二个问题,即如何辨别哪些像素会对当前像素做出贡献,需要考虑速度的方向、大小以及深度等多个因素。
这里依然采用的是McGuire的思路。

McGuire算法的步骤给出如上图所示:
- 首先针对当前像素,筛选出待采样范围内的所有sample,并判断哪些是前景,哪些是背景
- 之后基于如下的三个条件来计算出每个sample的叠加权重
- 前景数据需要满足其速度能够覆盖当前像素,即针对速度的方向与大小来看,移动轨迹与当前像素存在交集
- 背景数据也要满足速度能够覆盖当前像素
- 背景指的是深度低于当前像素的,为什么也能对当前像素产生贡献?
- 后面会说,这部分数据是用于替代被遮挡的背景数据的,用于实现inner blur
- sample的速度跟当前像素的速度相似的(指的是方向跟大小都相似?),这种情况下,这两个像素会相互贡献(遵循前面的前后scatter的逻辑)

针对前面的算法,这里做了改进,第一个改进点是提高各个sample的贡献的精确度。 参考上图两者的效果对比,左侧效果存在硬边,右侧的效果更为平滑。

对于某个像素而言,能够对它产生贡献的采样点会有一个非0的权重,这些权重不一定需要等于1。
之后我们做加权平均,并进行归一化,如上图所示。
再来看这个经典的水平移动的蓝色矩形。
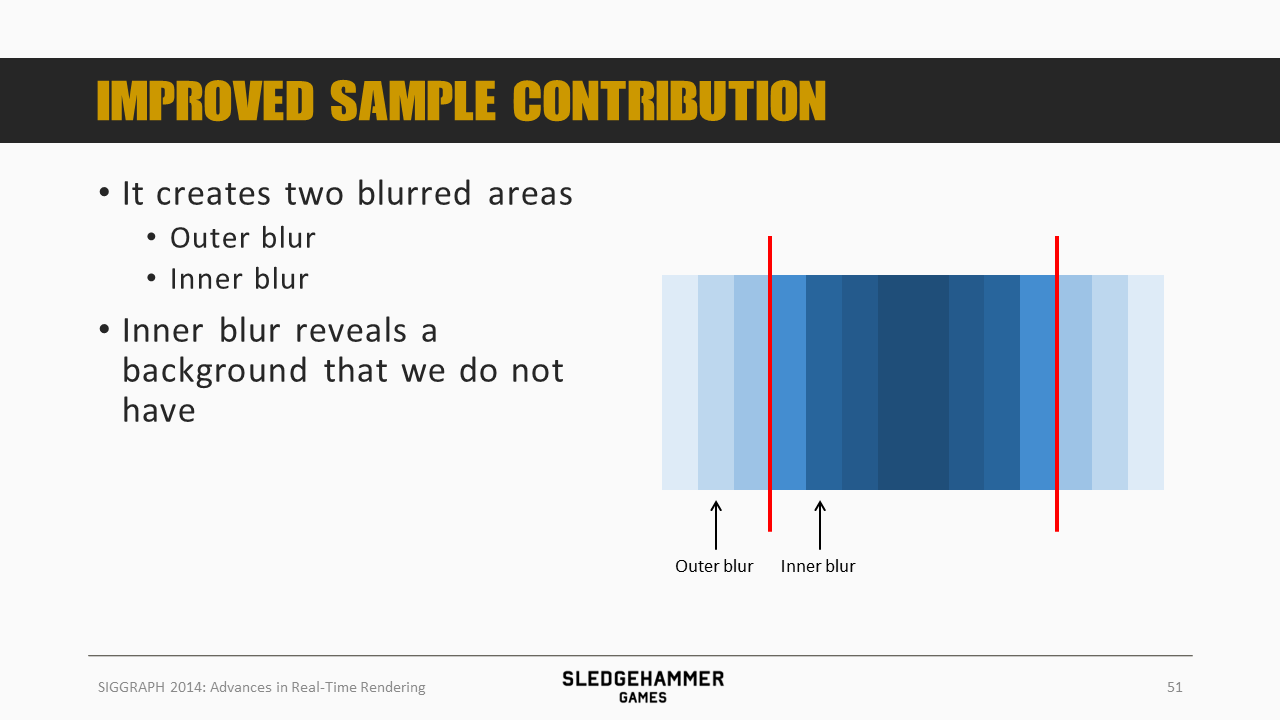
水平的移动会产生两个模糊的区域,分别是outer blur跟inner blur。其中inner blur需要混入我们所缺失的背景数据。
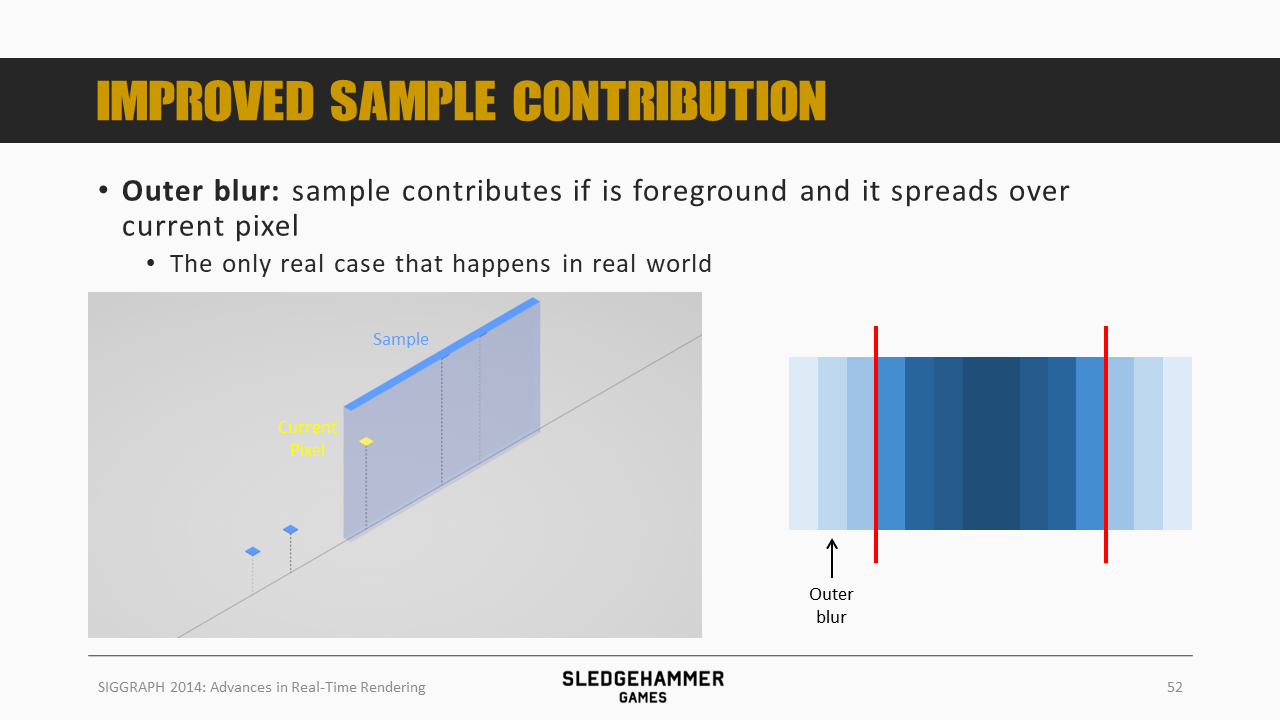
对于outer blur而言,如果周边的sample距离相机比当前像素近,并且其覆盖范围能够覆盖当前像素,那么就会对当前像素产生贡献,得到的结果就是outer blur。
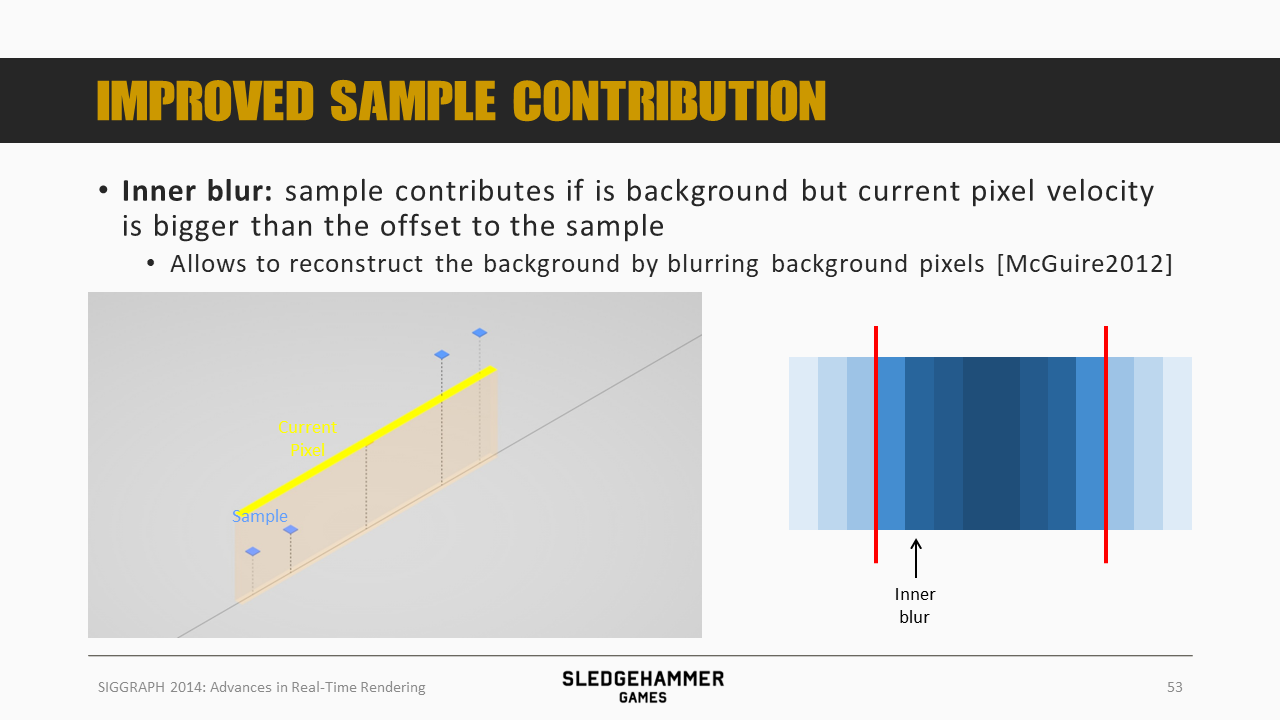
而inner blur则是在当前像素的速度覆盖范围内混合入背景数据而导致的模糊效果,而由于背景本身是缺失的,因此这里的做法是将相邻区域的背景数据合入进来。
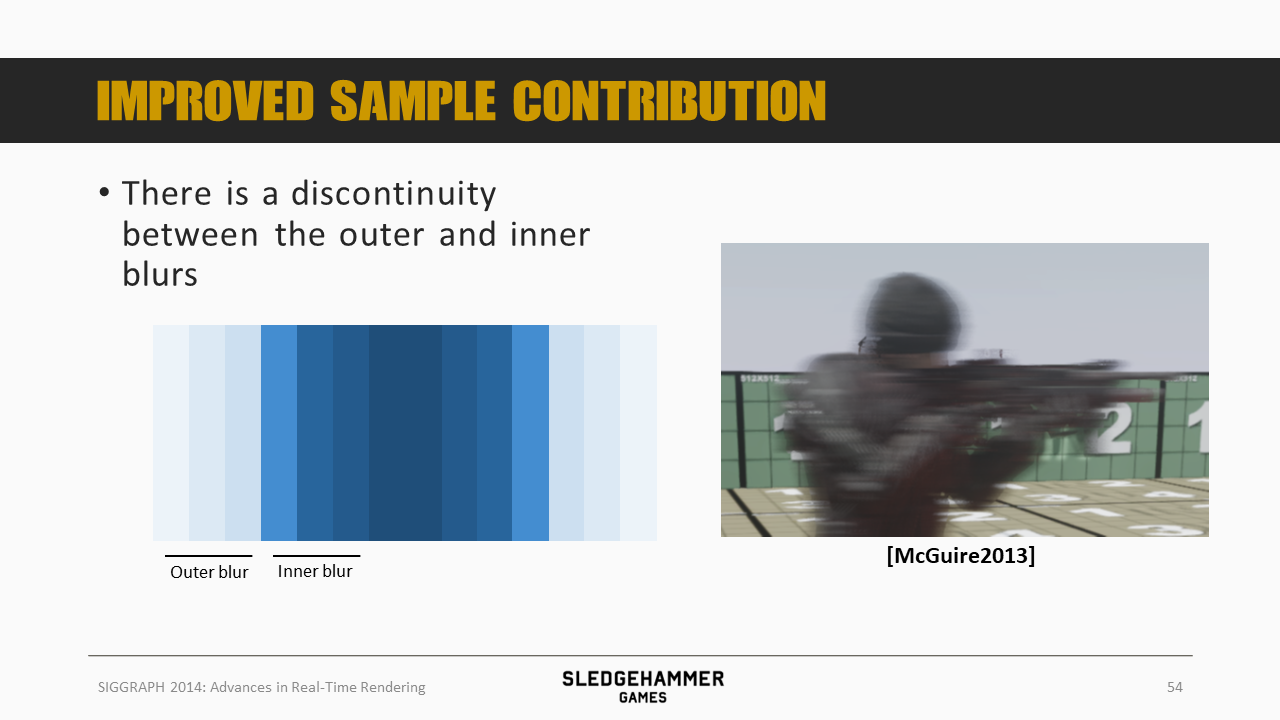
听起来好像还不错,不过inner blur跟outer blur之间会存在一条明显的界线,从而导致过渡较为生硬。
再来看这个原始的例子
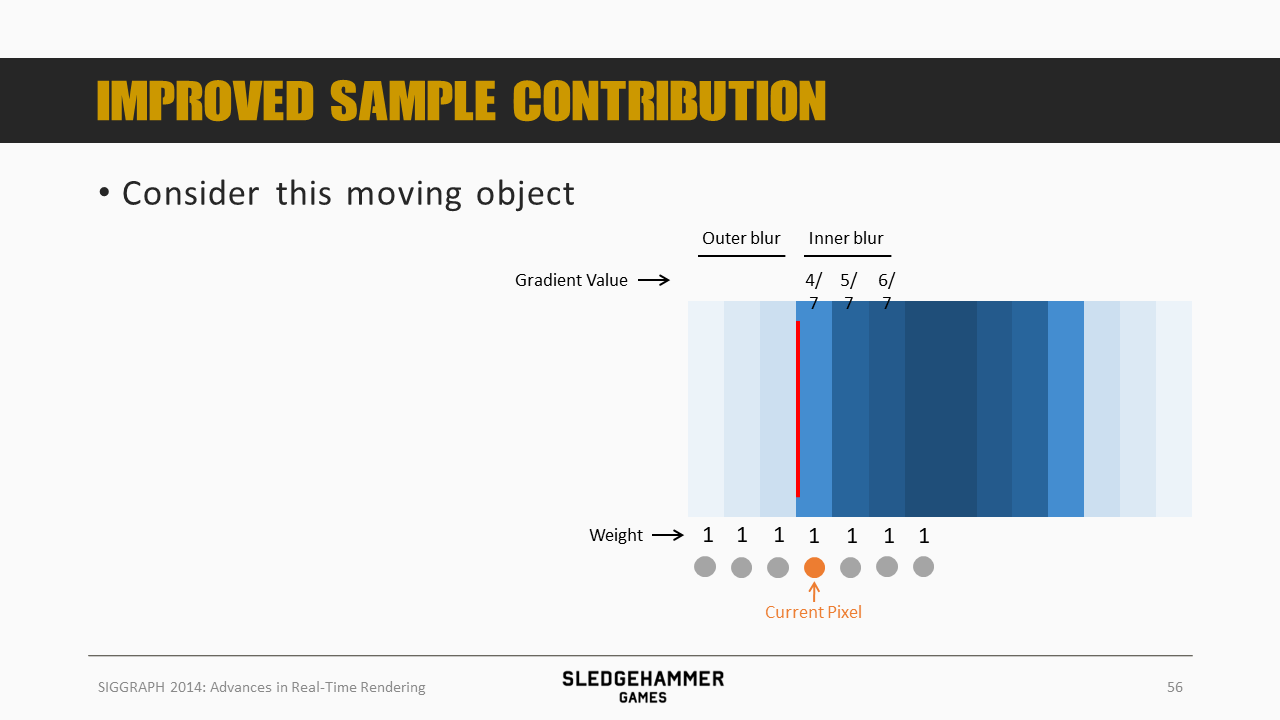
我们可以计算出橙色像素的覆盖范围,假设覆盖范围内每个像素的权重都是1,那么该像素的混合结果就是4/7,其后一个像素的混合结果为5/7、6/7,都还比较平滑。
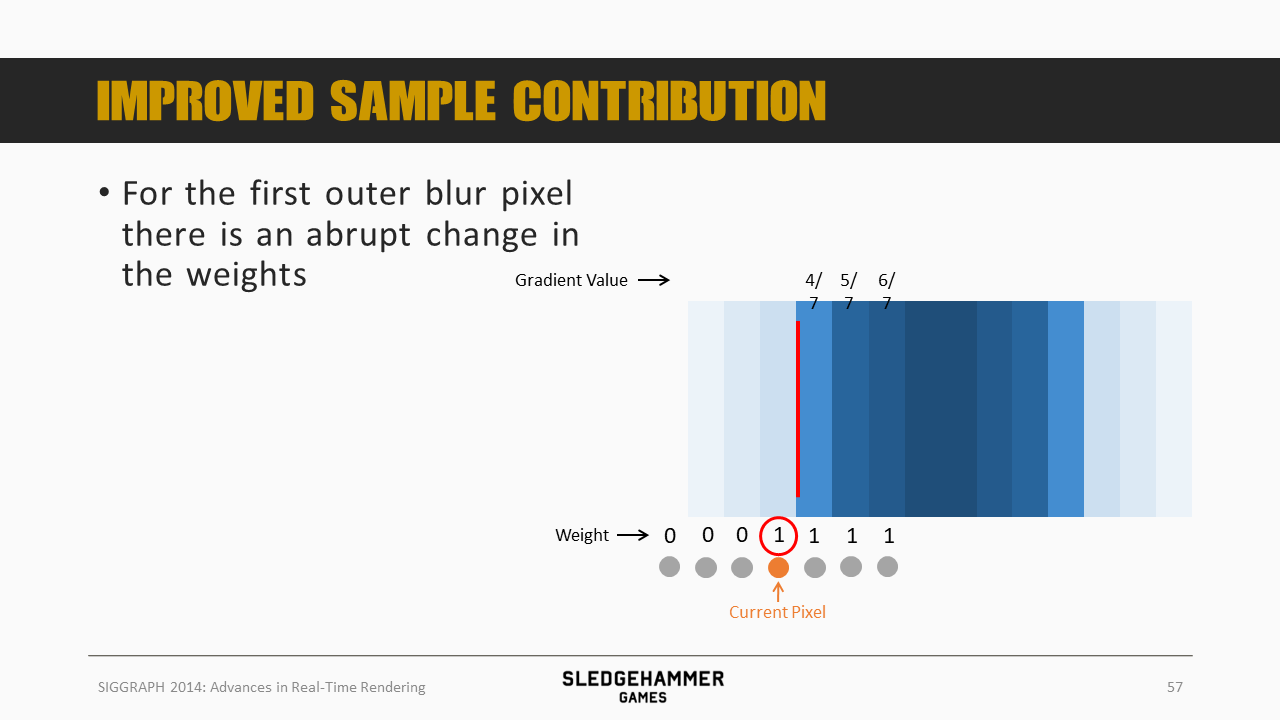
而来到outer blur的第一个像素,我们看到,左边的三个背景像素被拒绝了,不再参与到混合中,那么权重原来除以7,现在就变成除以4,导致结果变成了1,从而触发了前面的突变。
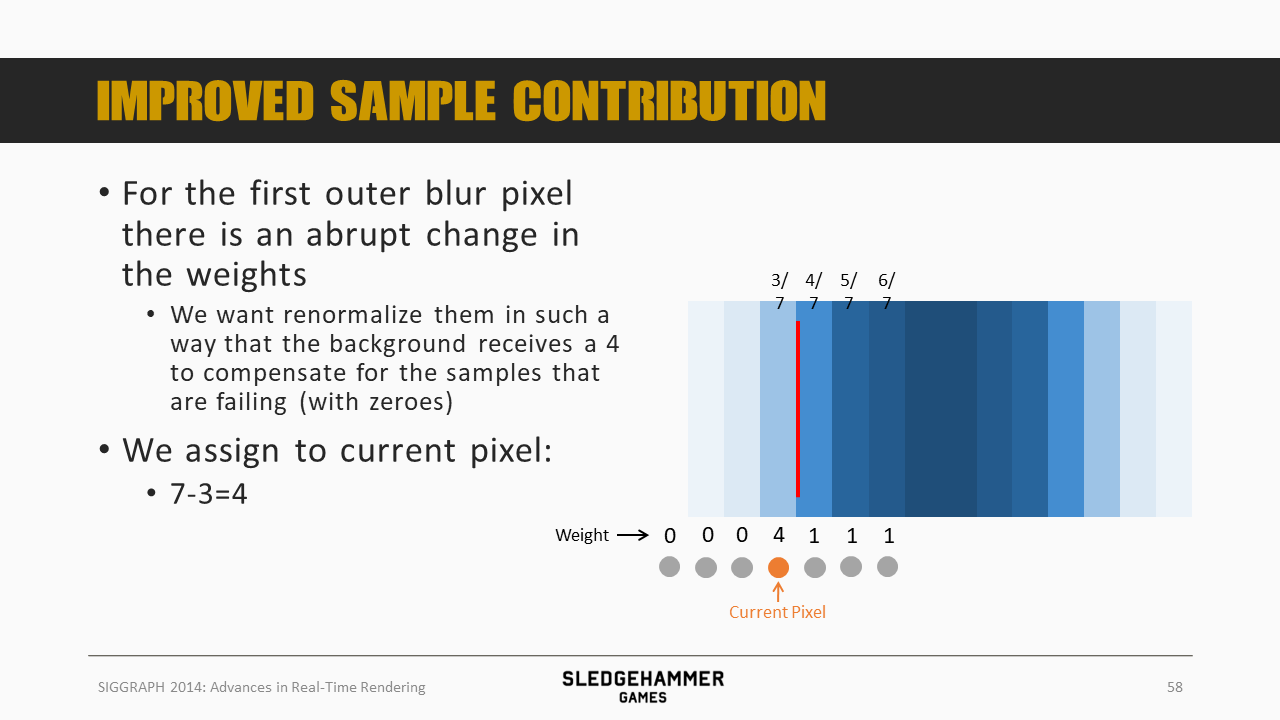
这里的解决方法,就是维持权重的稳定,将当前像素的权重从1改为4(4 = 7 - 3,可以理解为维持总权重的稳定,有值的采样点为3,那么当前像素的权重就要相应提高到4)
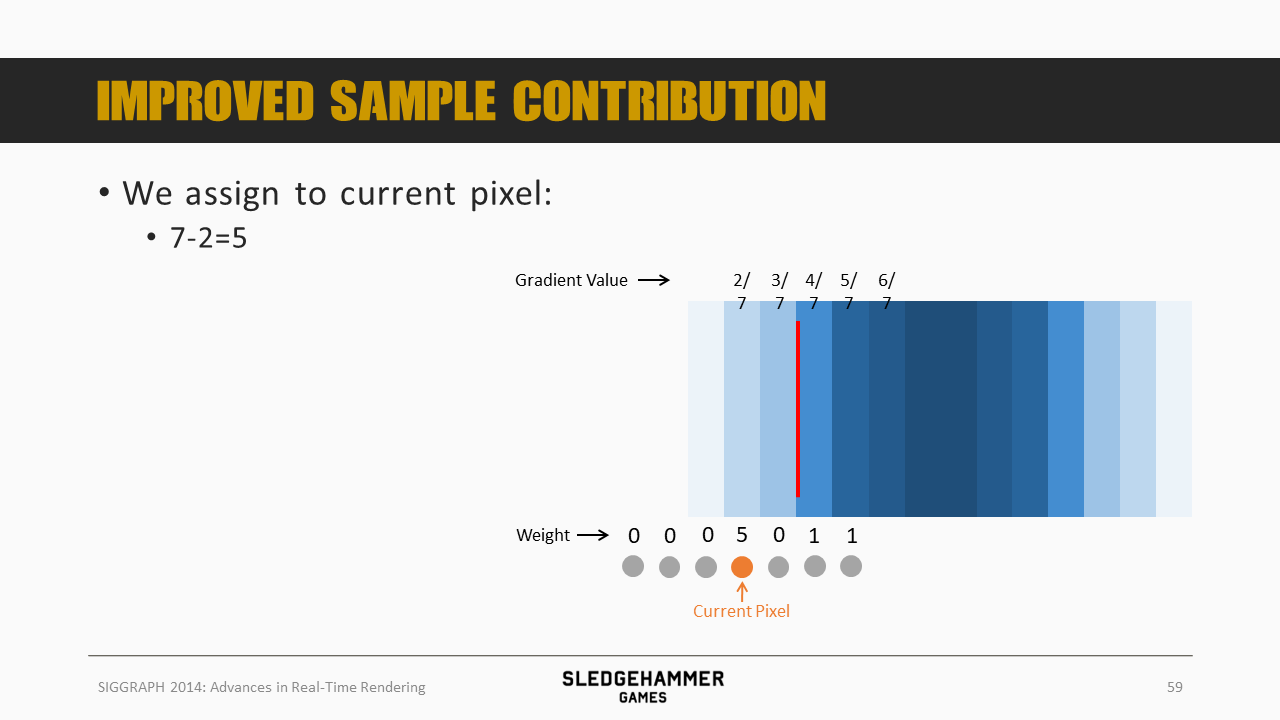
同样,再往前一个像素,本身的权重为5
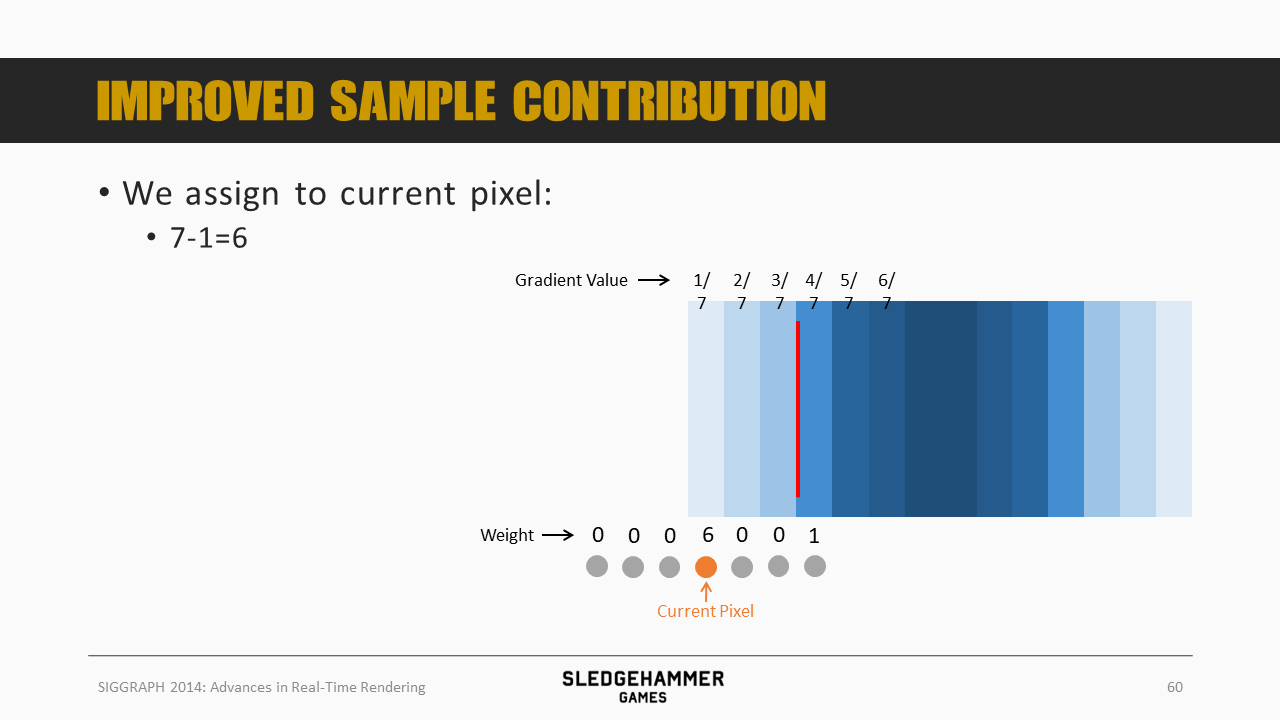
这里为6
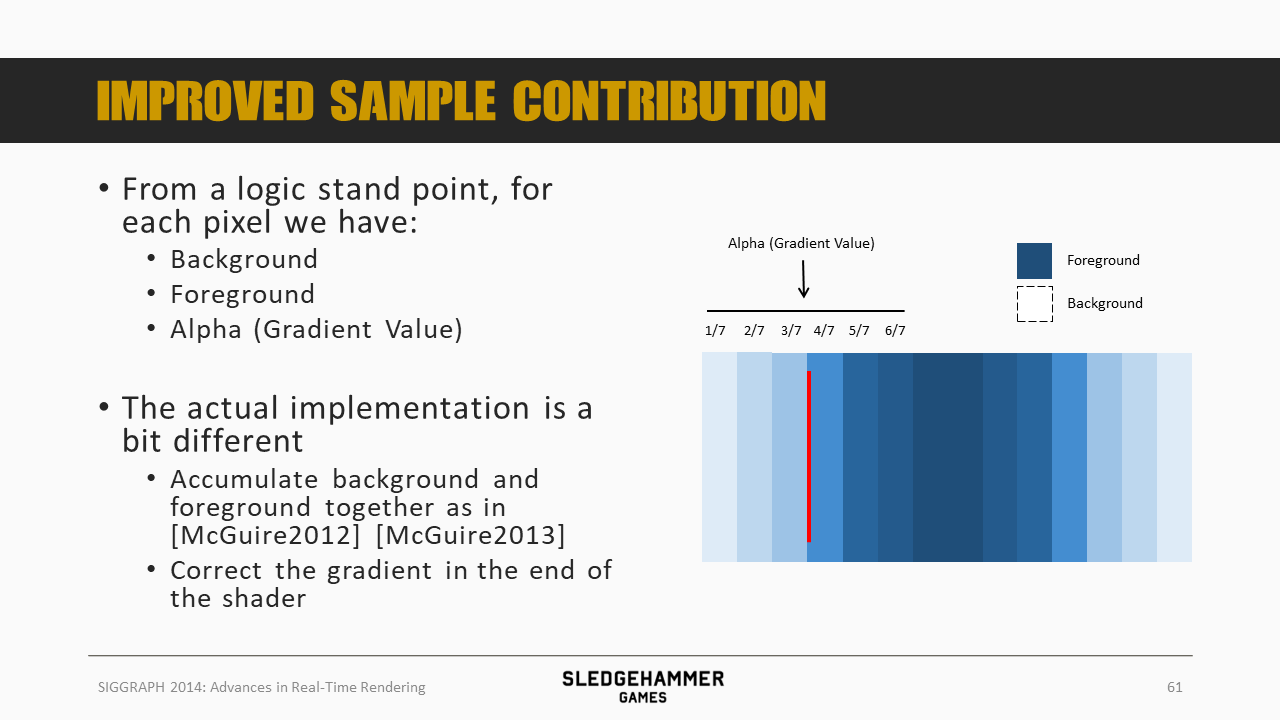
理论上,要按照前面的权重的方法对每个采样点做加权求和,不过实际实现的时候采用了一种简单的方法,就是:
- 按照McGuire的方法来做前景跟背景数据的累加
- 不过在累加后对累加结果做一个梯度处理


这里的代码给出了当前像素周边的各个sample的采样权重

这里给出了最终颜色的计算公式:color = foreground_color + (1 - foreground_alpha ) * background_color

这里将上述计算公式中的各个部分分别用图形的方式展示了出来,此外:
- 从性能考虑,这里只考虑一个模糊方向

实测发现,这个方法在背景变化低频的情况下表现是没问题的(因为相当于用可见部分的背景替代了不可见部分的背景),但是高频部分就会有问题。

主要原因是因为inner blur的背景数据是缺失的

这里的解决方法(trick)是将相邻区域的可见部分背景的权重做镜像处理,之所以这样做,是因为原来的问题是轮廓线两边的模糊程度不一致,那么我们只需要将两边的模糊程度调整为一致就行了嘛。

这里给出了具体的实现代码。

看看效果,这是McGuire的效果

这是调整了参与模糊的数据后的结果,总体来说模糊效果变得平滑,但是部分背景区域也存在不平滑的现象。

之后做了镜像权重处理的效果,不平滑问题得到了缓解。

将模糊结果跟原始图像混合后,就得到了这个效果。

这里给了一个展示视频。

第二项优化点,是画面质量,即通过不同的采样pattern来提升效果。

主要采取了上述四种采样pattern,这里是通过在采样的时候通过一个噪声函数调整采样offset来实现的

比如一个常量的噪声函数就返回一个常数值,效果如上图所示,有很明显的问题,表现为pattern比较明显

将噪声函数替换成上述实现(平方算法)后,效果就好多了

采用dither方案,效果更好了,这里对各种dither pattern做了对比,最后发现checkboard pattern最好。

如果在时域上再做一次dither,即奇偶两帧分别采用不同的pattern,效果还会进一步提升。

如果采用的是non-uniform的采样方案,会导致模糊中心区域的锐利的线条。这里给出的解决方法是将采样点(灰色点)与当前像素做一个错位(水平+垂直),相当于将一个像素的数据分散到相邻的采样计算中,从而避免了前面的问题。

总结一下:
- 在采样数不足的时候,通过添加噪声的方式可以有效提升画面质量
- 通过dither的方式加上时域复用还可以进一步提升画面品质

上述介绍的方案,相对于原始McGuire的方案而言,由于处理的case从3个降低到2个,所以性能上是有提升的,但是这里还有优化的空间。

这里做的一个优化是,将此前tile中存储的max depth改成min/max两个值,并基于两者的差来判断是否需要执行快速路径。
这里的视频展示中,当静止的时候,基本上就是蓝色的,需要走early exit路径,而在移动的时候,基本上都是color loop(快速路径),只有少部分是复杂的红色slow path。

在具体的实现上,这里还有一些建议:
- 最大的速度从原来的2D计算,变成两个1D计算(这种算法不只是可以用于模糊,所有类似的计算都可以)
- 将速度跟depth放到一张buffer中,从而降低shader采样数
- 对tile采样的坐标做dither处理,从而可以有效降低tile的pattern表现
- 使用point sampling避免线性混合导致的bleeding问题

接下来看看DOF,其中所需要的计算逻辑很多在前面运动模糊中都已经覆盖了。

虽然两者在具体的实现原理上有极大的相似之处,但实际情况还是有些区别,比如运动模糊由于是运动物体,很多问题会被掩盖,放到DOF下,这些问题就容易暴露。
在实际执行层面,运动模糊其实是一种单层的方法,这里针对DOF就需要一个双层方法。

这里介绍了工作的复杂情况
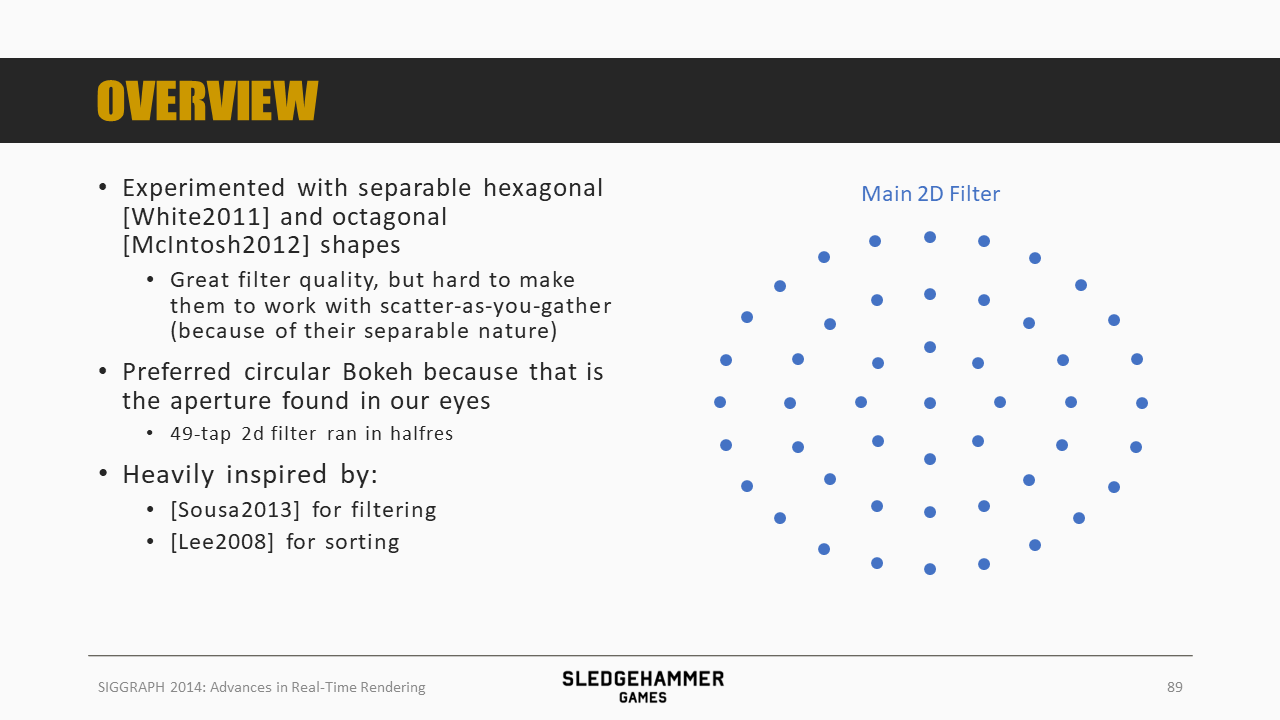
最开始先尝试了六边形或者八边形的模糊形状,效果很好,不过不能很好的匹配前面的scatter-as-you-gather的实现方案(为啥?因为不知道要将当前像素的数据贡献给哪些像素)。
最终采用的是圆形的Bokeh方案,在半分辨率下每个像素采样49次。

先对DOF的问题做一个总结,总的来说问题跟运动模糊是类似的,不同的是程度更为严重:
- Scatter-as-you-gather应用的bleeding问题,通过tile划分加max coc来解决
- 采样质量不足问题
- 性能问题,需要49个颜色采样以及另外49个数据采样
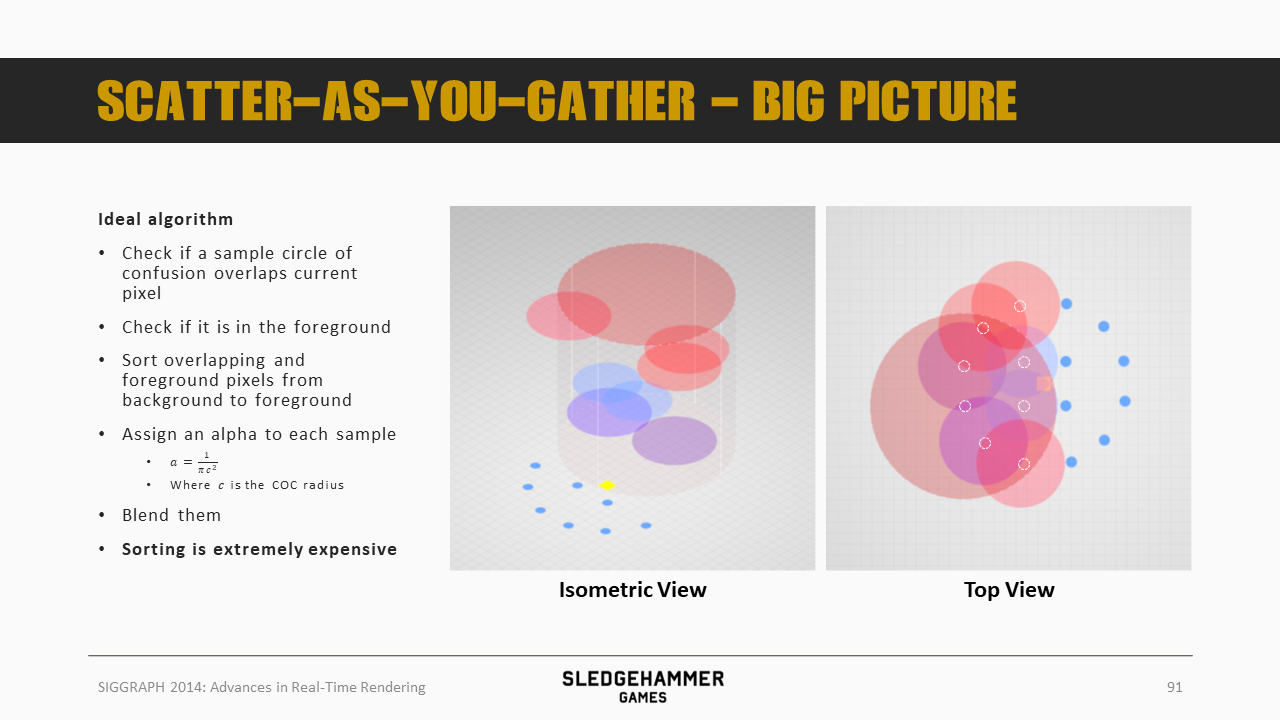
这里给出DOF的计算步骤,参考最右边的图,其中橙色方块表示当前像素,蓝色、白色的圈表示参与贡献的sample(每个白色sample都有一个较大的CoC半径,蓝色表示的是背景,此处未做blur):
- 判断某个sample是否会覆盖当前像素(即以该sample为中心,以CoC半径为半径看是否相交,这里用于判断sample是否产生贡献)
- 判断sample相对于当前像素而言,是否是前景数据
- 将overlapping以及前景像素放在一起,按照从后到前的顺序进行排序(这一步计算比较费)
- 对每个sample赋予一个alpha混合权重,公式如上(CoC半径是跟sample而不是跟当前pixel走的。。)
- 基于alpha完成混合
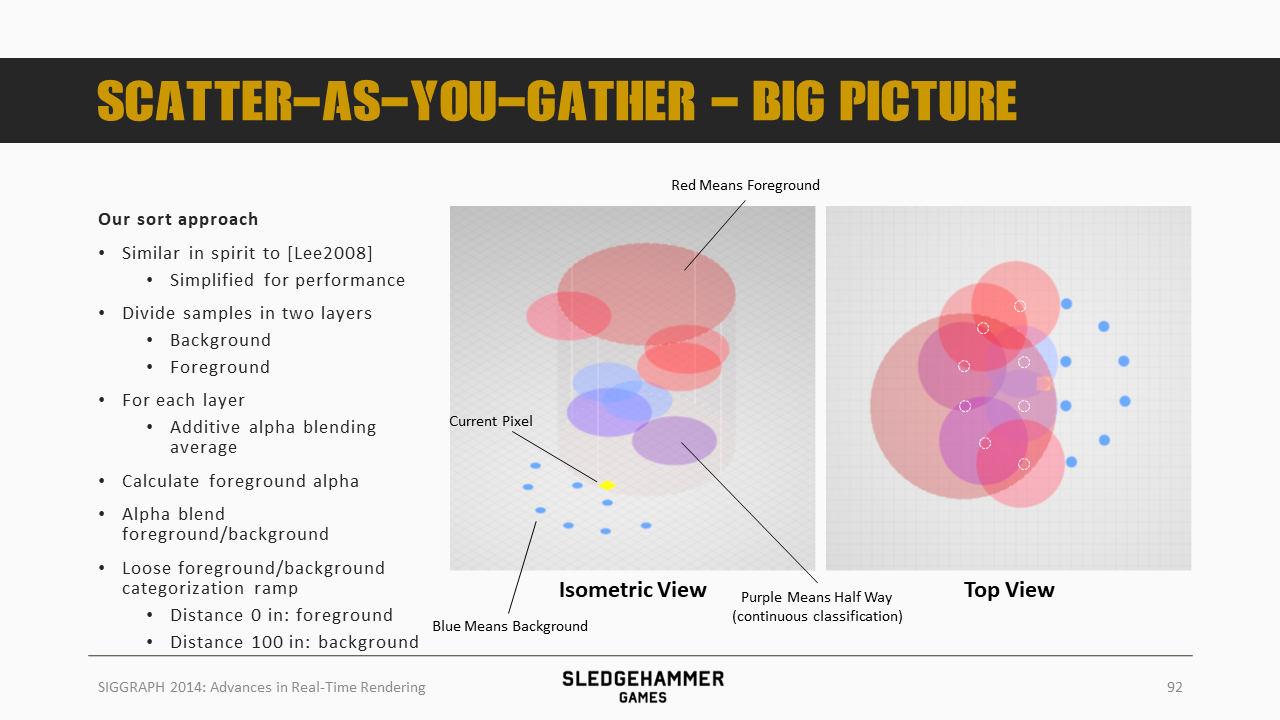
这里对方法做了一个简化:
- 将samples分割成前景跟背景两层(图中用颜色标出,蓝色是背景,红色是前景),不过虽然分为两层,但是距离上是平滑过去的,而非二分
- 从性能考虑,这个划分是基于tile上的最小最大depth来执行的
- 对每一层的sample分别做additive的alpha blending
- 对于前景,计算其透明度(即有多少比例的光线从背后透过来)
- 基于上述alpha,对前景与背景数据做混合

这里做一个可视化的展示,先来看看背景数据

然后这是前景数据

这是两者混合的alpha数据

基于上述三个数据混合后的结果如上图所示。

sample覆盖范围采用的依然是前面运动模糊的tiling策略,同样需要做3x3的tile过滤,取得最大的CoC以及到相机最近的深度数据(用来做前景跟背景的区分)。

在执行main filter之前,这里增加了一个presort pass(这里的presort,其实是标注前景跟背景),这个pass会计算出每个像素的CoC、前景跟背景的SampleAlpha数据,存入到一个R11G11B10的PreSort Buffer中。
这里是通过与前面的closest depth来比对,判断是前景还是背景的。
这个pass的作用是避免main filter pass中的ALU & VGPR计算压力(为啥可以避免?是因为就只需要做一遍,之后被多次使用?)

这里的累加结果会写入到两个float4中,分别存储前景跟背景的数据,其中RGB存储颜色,A存储权重。
前景跟背景混合的alpha来自于前景的a通道,不过,scatter-as-you-gather方法还需要做归一化(为什么scatter方法不用?),公式如上图所示。

DOF不同于运动模糊,不需要混合被前景遮挡的背景数据,比如上图中给的右边小图的例子,只需要模糊前景的角色。
如果不做处理,就会在边缘混合进来背景的数据,这是不希望看到的。
这里的做法是对alpha做一个remapping,不影响中间区域的alpha数值,保持前景混合的结果(使用背景数据,不过背景本身被前景遮挡,其实也就是前景了),而调整边缘位置的alpha数值,使之更多的使用前景数据,从而避免混合进来更多的背景数据。

这个是结果

alpha的remapping也会带来一些不良影响,主要的问题就是这个操作会导致模糊后物体变得肥胖或者纤细,看起来不自然。
从上面的分析看到,这里可以针对不同的情况采用不同的remapping策略,从而得到更为自然的模糊效果。
这里给了个视频,展示了最终的效果,前景(武器)的边缘锐利程度得到了很好的保留。

这里来看下采样点不足的问题,主要通过两个方法解决(展示了两种优化策略的收益):
- 在滤波之前,先做一次预滤波
- 滤波之后,叠加一个median(中值滤波),进一步降低噪声
下面看下这两种策略的具体实施细节。
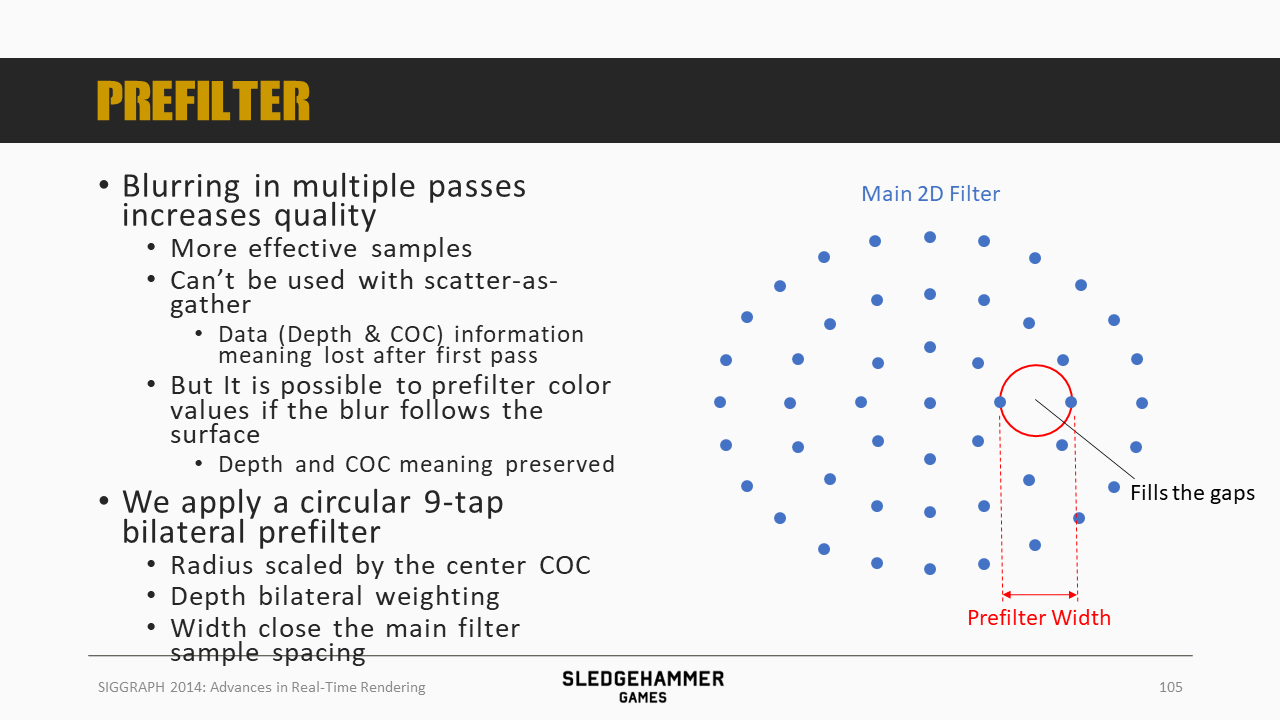
一个需要大量采样点的滤波,可以转化为多次少量采样点的滤波(乘法原则)。
不过这种方法不适合于Scatter-as-you-gather方法,这是因为这种方法的输入参数(Depth & CoC)在完成第一次滤波后,数据的物理意义就丢失了。
要想保留其物理意义,就需要在滤波的时候做特殊处理,比如沿着物体的表面进行滤波(depth aware)。
这里采用了一个9 tap的预滤波方法,会根据中心的CoC调整滤波半径,同时权重会考虑深度的影响,滤波的宽度正好可以填充sample之间的孔隙。

这里对前面的简要概括做了一下细节的补充:
- 这里会把数据分为两层
- 为了提升效率,部分采样点在满足下述条件的时候会被认为是可接受的:
- 采样点跟center tap的前、背景属性是相同的(同为前景或者同为背景)
- 也就是说,允许层内混合,不支持跨层混合
- 采样点跟center tap的前、背景属性是相同的(同为前景或者同为背景)

这里的预滤波采用的是Karis average算子,用稳定性换清晰度。左右两边是传统方案跟预滤波方案,可以发现预滤波方案可以有效滤除高光的闪烁。
预滤波之后,就进入了main filter pass。
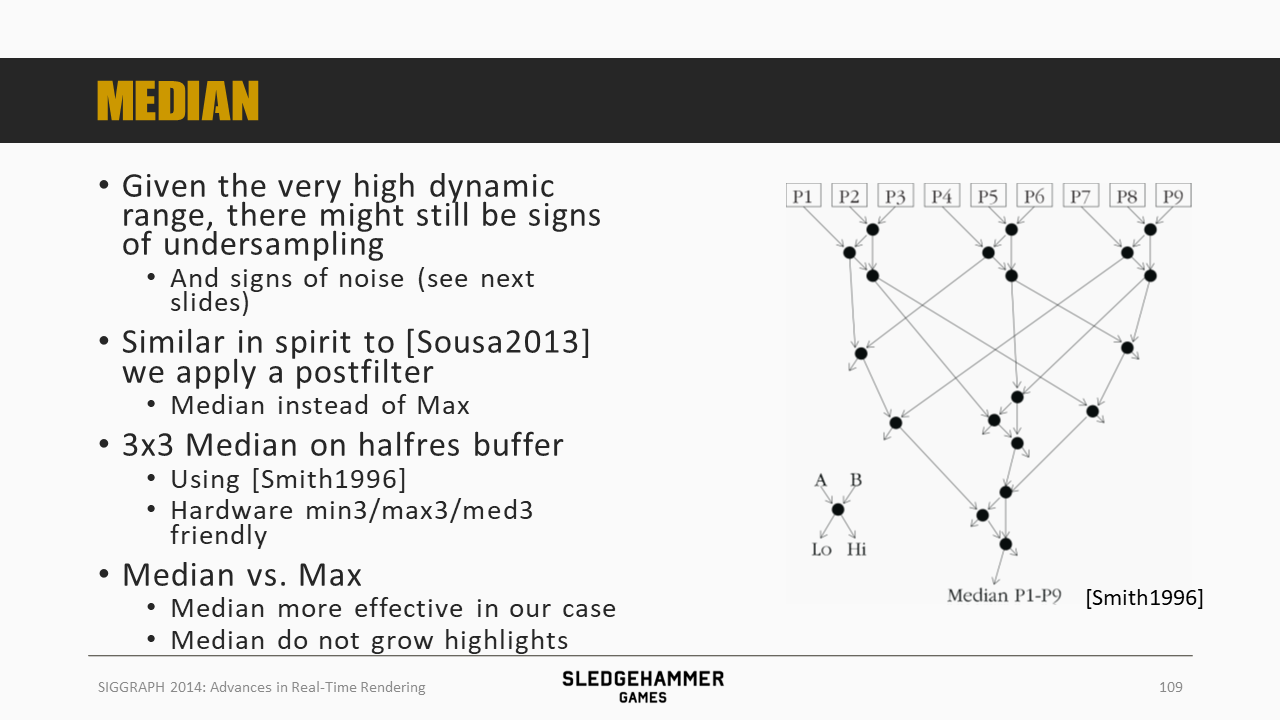
即使是HDR,依然存在采样率不足、噪声的迹象(?),这里的解决方法是类似Sousa 2013的做法,再做一次后滤波,不过这里的滤波算子用的是中值滤波,而非最大值的滤波,原因是中值效率更高,且不会影响高光效果。
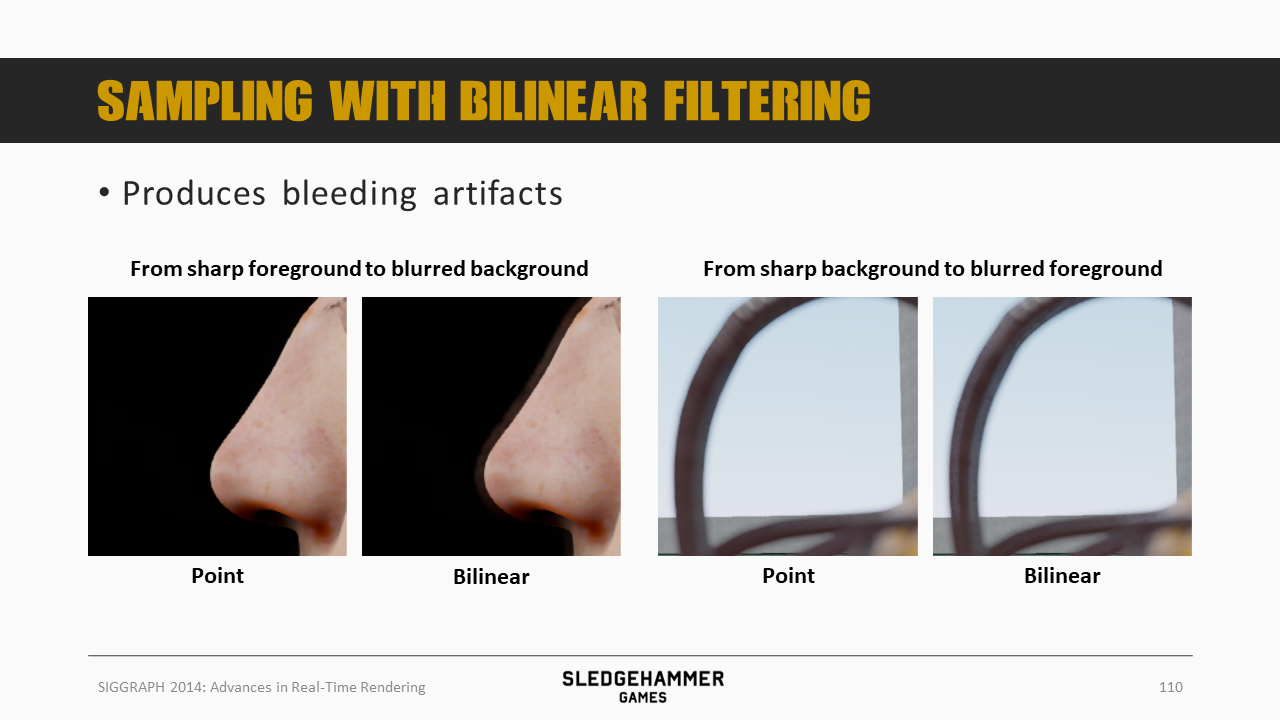
采用双线性滤波会导致bleeding问题

bleeding问题可以通过CoC premultiply策略解决(具体是?),不过这个解决方案对于极端情况表现比较好,中间区域则会有失败的可能(尤其是HDR)。
需要RGBA16格式的buffer,会有较多的显存消耗,且跟只考虑color的优化计算逻辑不兼容

预滤波跟滤波(main)pass的详细设置如上所示:
- 预滤波时,颜色跟深度的采样策略不相同
- 滤波pass
- 正常情况,颜色buffer跟presort buffer都是point sampling,并添加随机offset
- 对于fast tile而言,即只有颜色,则只采用双线性采样加随机offset

也尝试过一个变体版本,不过计算消耗会高一些,且前景的alpha数值相比期望数值会偏低。
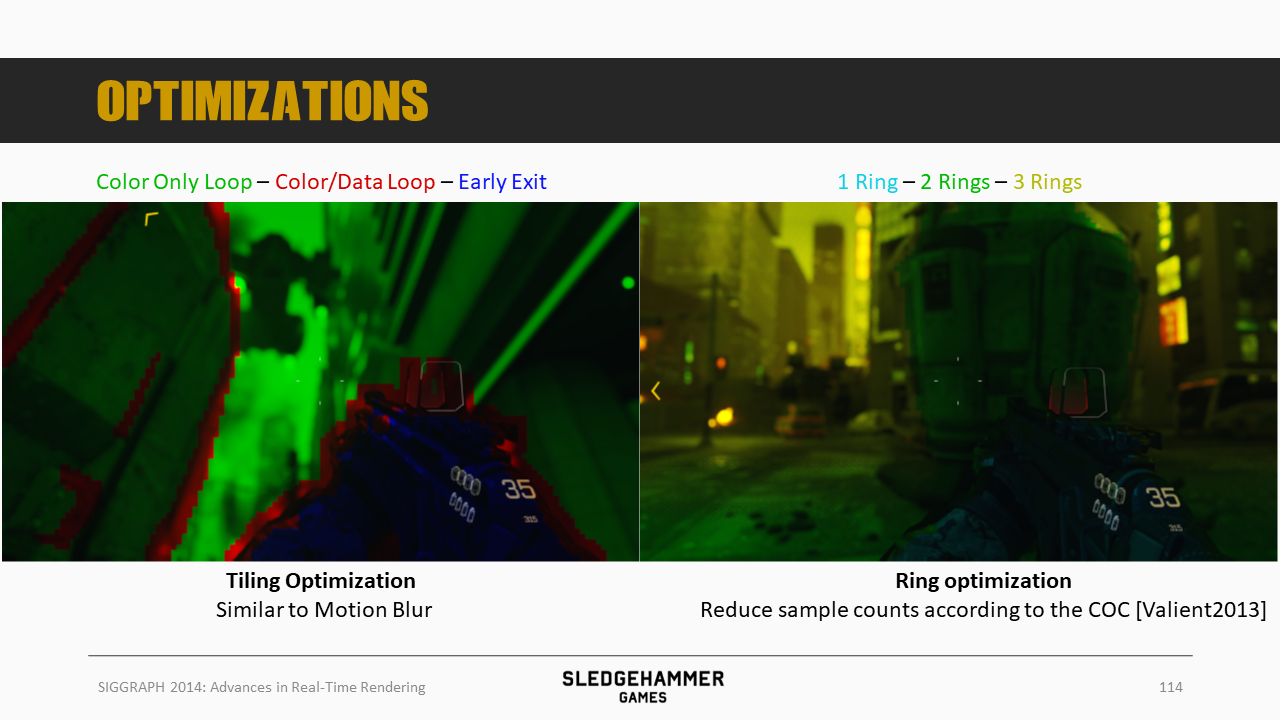
这里的优化(性能)策略类似于运动模糊的优化策略,分三层,每层采用不同的计算分支。
此外,还有一个Ring Optimization策略,根据CoC的数值来调整采样数(参考Valient 2013)。

将下采样、滤波以及presort放到同一个pass中完成:
- 下采样的时候,选择最远的sample来降低半分辨率导致的光晕(haloing)问题
- prefilter跟presort基于同一个depth buffer完成
Main pass输出的颜色跟alpha也是半分辨率的。
这俩(颜色跟alpha)都会通过中值滤波处理一轮。

这里对总体的滤波逻辑做了更细致的说明。

最后一个部分跟后处理关系不大,会介绍一下阴影采样的方法。

60 fps的帧率要求,导致阴影采样数就不能过多,这里尝试过对每个像素按照旋转泊松圆盘做随机偏移的方法,在8个采样数的情况下,表现也不是太好,同时在移动的时候质量还不稳定。

最常用的随机公式是将数值与某个magic number做多次点乘。

对随机噪声生成器做了多种尝试,发现了一种介于dithered跟random之间的方法,这里称之为Interleaved Gradient Noise。
基于这个方法来对采样点做旋转,得到的结果相当不错:
- 能够像随机噪声一样,数值分布域较广
- 结果在时域上是稳定的,兼得了dithered的优点

噪声函数会产出interleaved gradients,也就意味着匀速移动的物件,其阴影采样的采样点是平滑旋转的(?),而如果要想让这个方法适用于静态图片,这里还需要在水平方向上做一个偏移。


这里展示了该方法跟随机噪声方法的区别,质量明显更胜一筹。

因为这个方法是空间连贯的,因此适合通过模糊来做平滑。
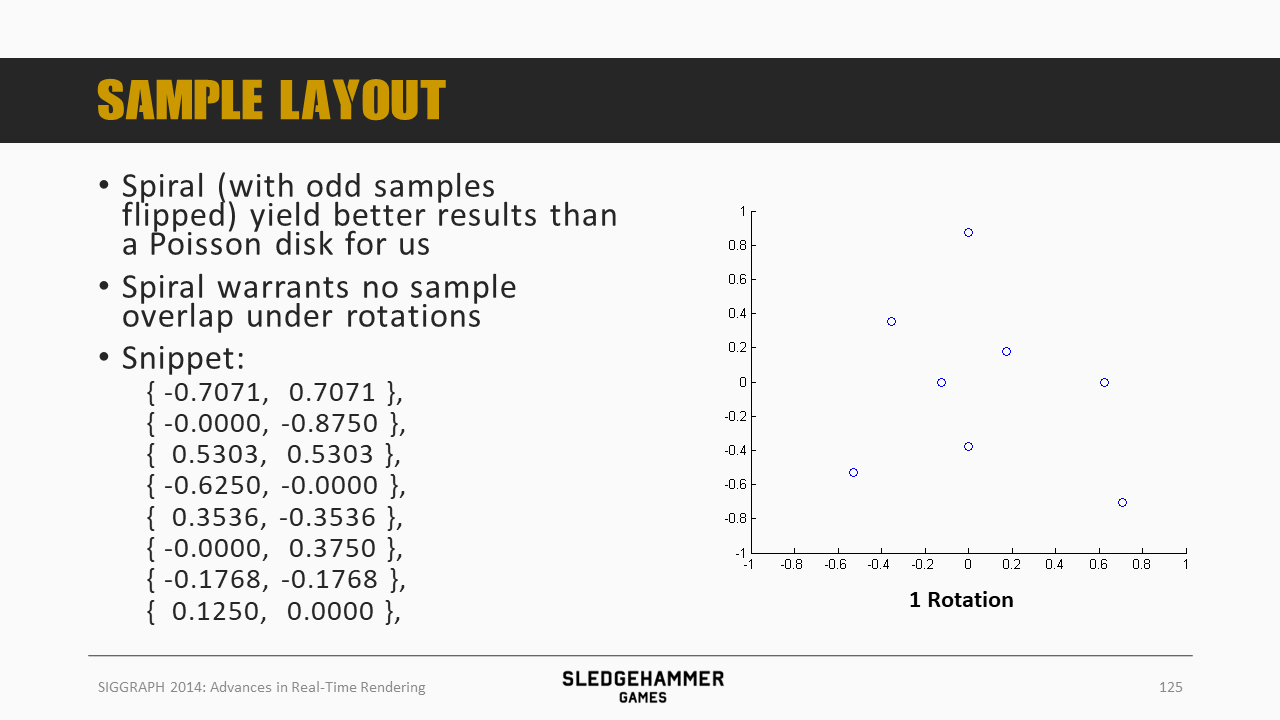
采样点是按照spiral(螺旋)分布的,说是比泊松圆盘的分布方法更合适。
螺旋采样可以确保在旋转的时候,样本不会重叠,上图给的数据,绘制出来大致如下图所示:
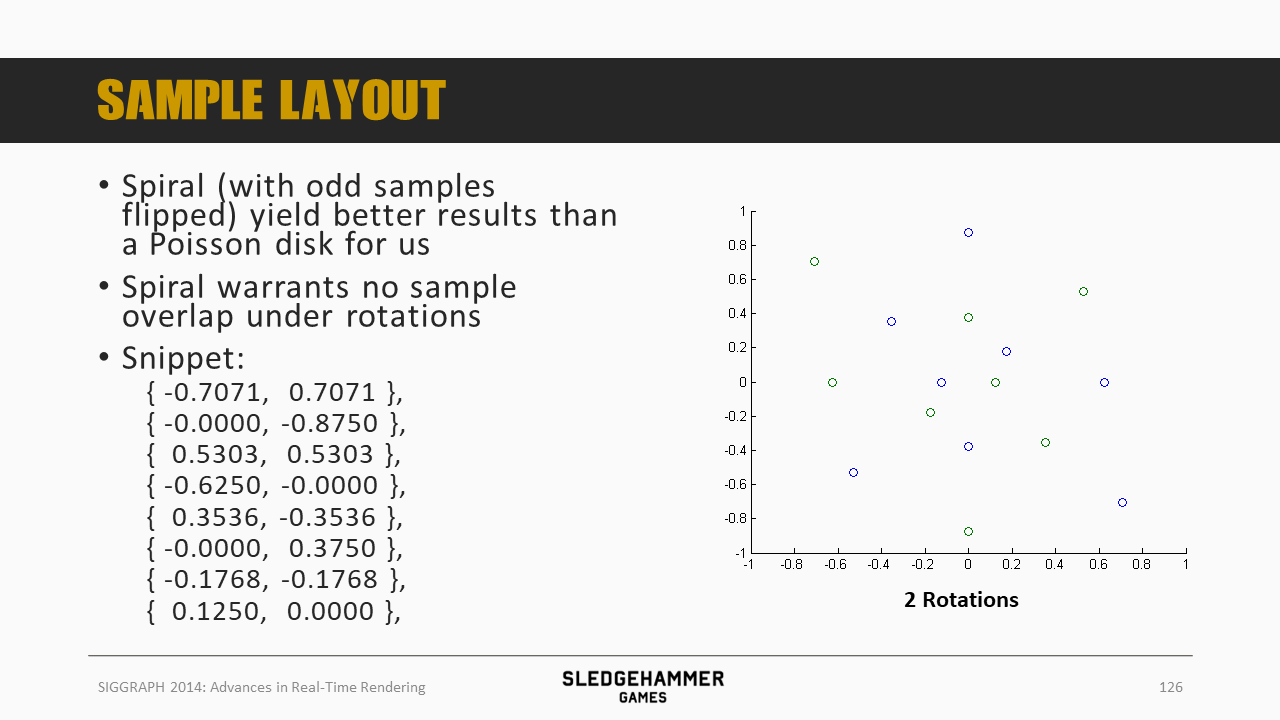
将前面的采样点做一个旋转
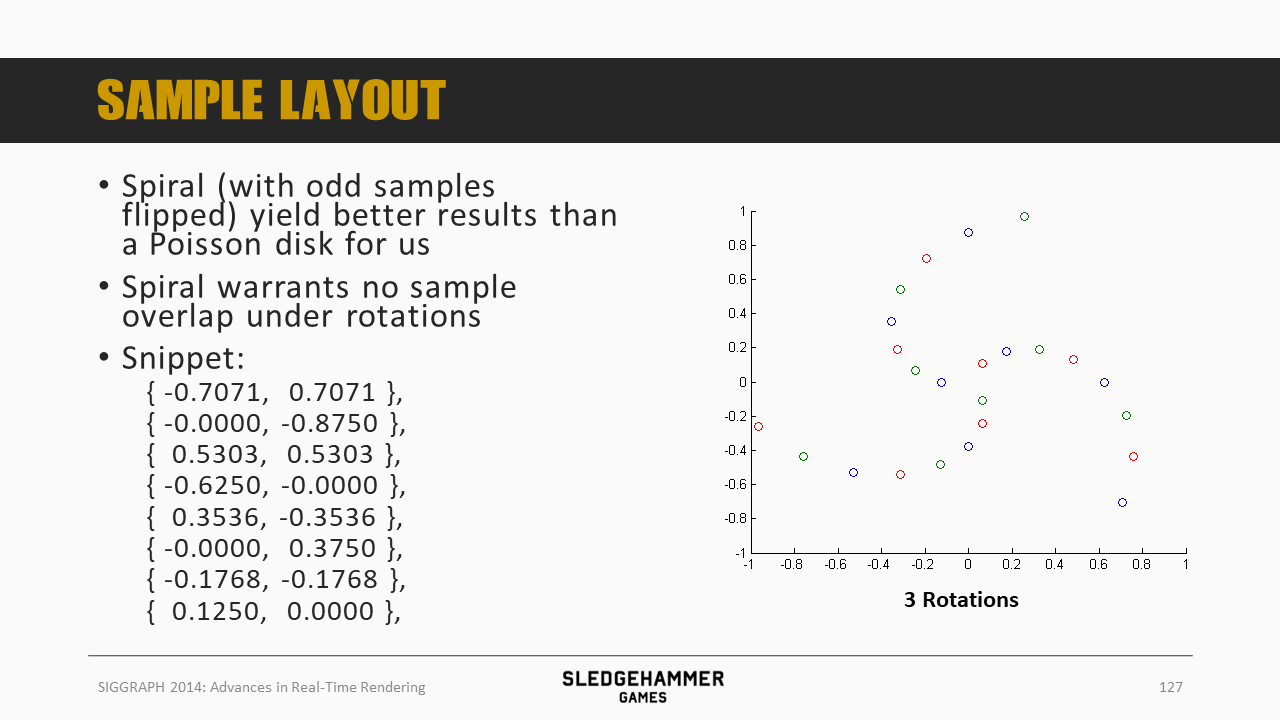
三套旋转样本叠加
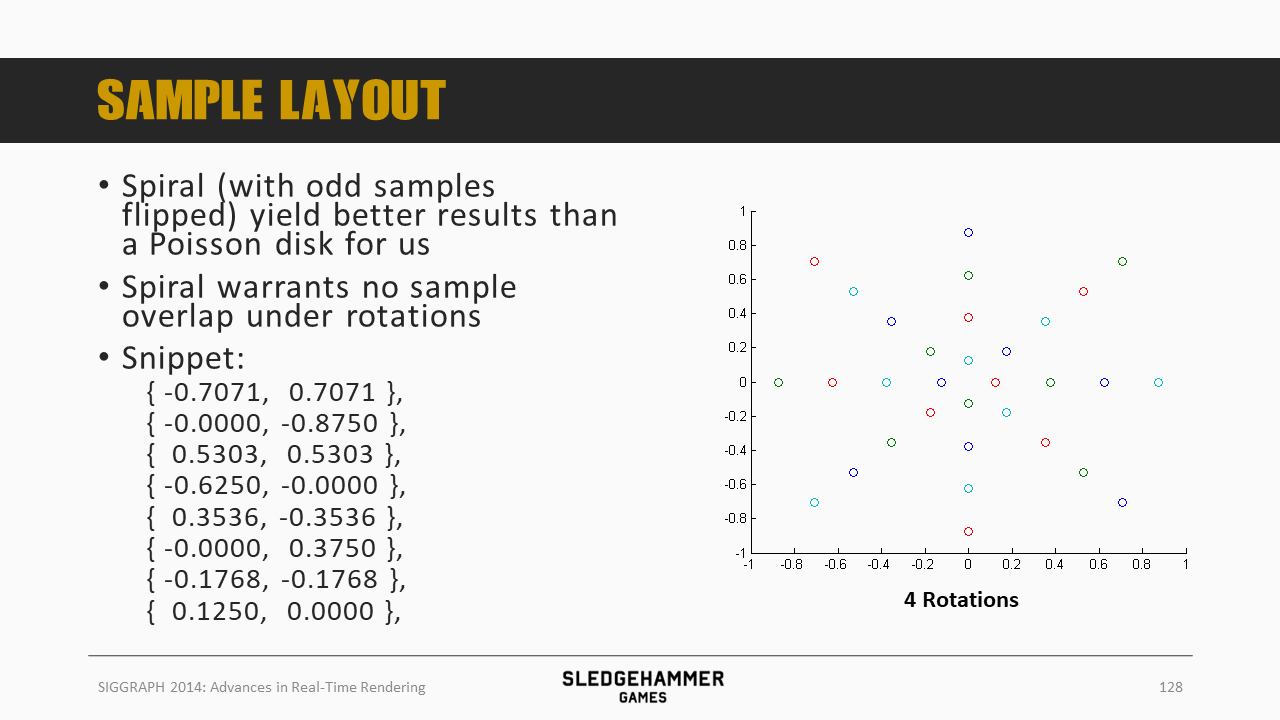
四套
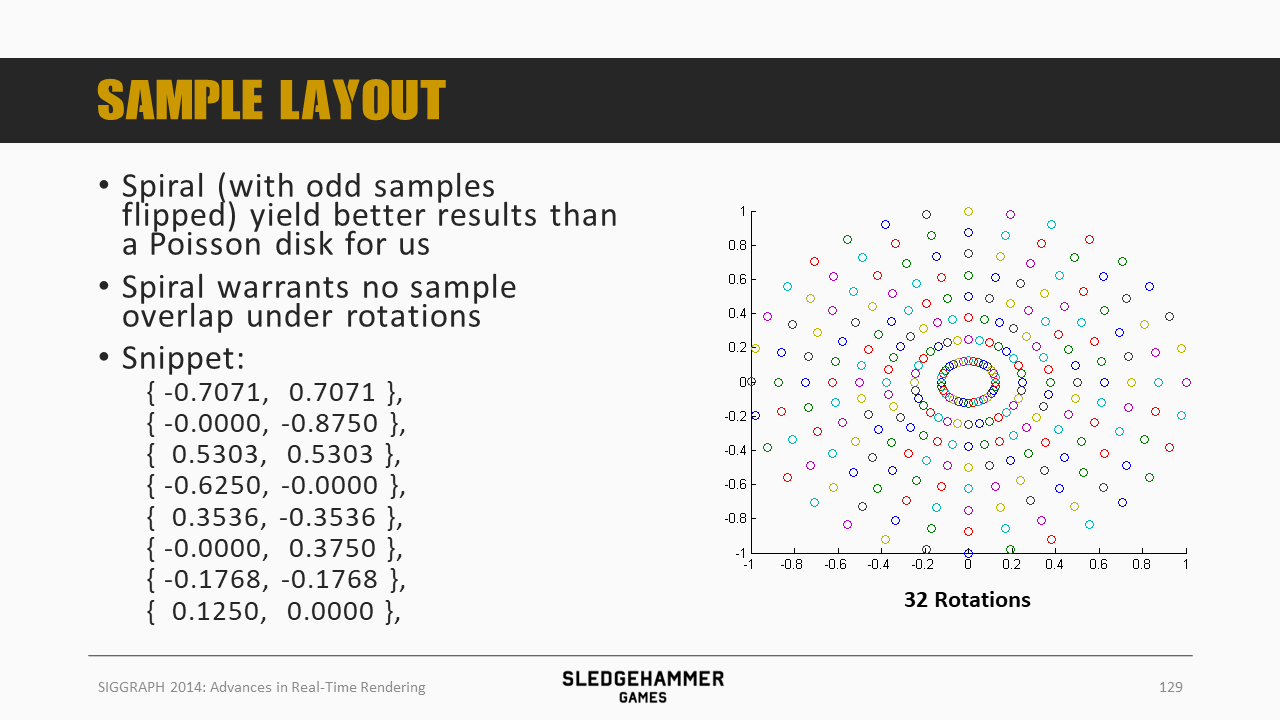
32套
把这些综合到一起,就得到了一套能够随着时间平滑旋转的样本,如果帧率够高的话,就能在一个位置整合尽可能多的样本,从而得到平滑的阴影效果。

这个方法不只是可以用于阴影,还可以用于任何需要较多采样来提升质量的技术上,比如SSAO。

这里给下XBOX ONE主机上,前面各个计算的时间消耗(如果在手游上也是60fps为目标的话,那这个数据就可以作为参考了)。




将次表面散射的内容放到了bonus slides中。

采用的次表面散射方案是Jimenez 2013中的Separable次表面散射方法:
- 通过一个双pass的屏幕空间模糊实现(水平+垂直方向)
- 之后通过噪声来掩盖采样数不足的问题(前面的随机旋转策略?)
- 滤波的形状是两个高斯之和:
- 近景散射R1
- 远景散射R2
- 混合因子W

具体而言,在Mikklesen 2010的皮肤渲染方法(伪分离交叉双边线性滤波)基础上做了一系列改进:
- 使用了importance sampling方案:9采样点,不过大部分情况下7个就够了
- 改进后的版本不再需要通过hack的方法来计算depth差异(因为基础版本还不明白,这里的细节就先不展开了)

再来看看Bloom的实现

经典实现分为如下几步:
- 通过阈值过滤出高光部分
- 将高光部分做下采样,得到mipmap pyramid
- 将每个mipmap都上采样到原始分辨率,这个过程会自动完成模糊
- 将各个上采样后的mipmap叠加到原始图片上
- 高斯模糊?

这里的实现是在经典实现上做了一些优化:
- 期望通过一种非侵入的方式(原生)来提升wider dynamic range(HDR)的感受
- 这里的输入是未经过阈值滤波的输入
- 思路参考 Ward 1997
- 颜色(亮度)范围是PBR的,非常高
- 这样有助于实现更为自然的bloom效果,模拟人眼感受
- 人眼感知到的散射,比如SSS,其实是未做过阈值滤波的
- 期望效果是时域稳定的

时域之所以不稳定,主要有如下几个因素:
- 滤波,包括下采样跟上采样,都有可能导致时域的不稳定
- 萤火现象,部分超亮的次像素(尺度),会导致前后两帧的计算结果存在差异,从而导致不稳定

解决方案给出如上(分成四个pass?每个pass都需要经过下采样跟上采样,同时不同pass,会在不同的阶段做滤波处理),总的来说就是参考Mittring 2012的方案,对下采样跟上采样结果都做滤波处理:
- 下采样滤波可以滤除锯齿效果
- 上采样滤波则可以提升图片质量,得到更平滑的结果
在实现的时候,模糊跟下采样(上采样组合)可以在一个pass中完成。

滤波方案这里也做了比对,双线性滤波质量较差,Bicubic表现也不太好,高斯是最好的
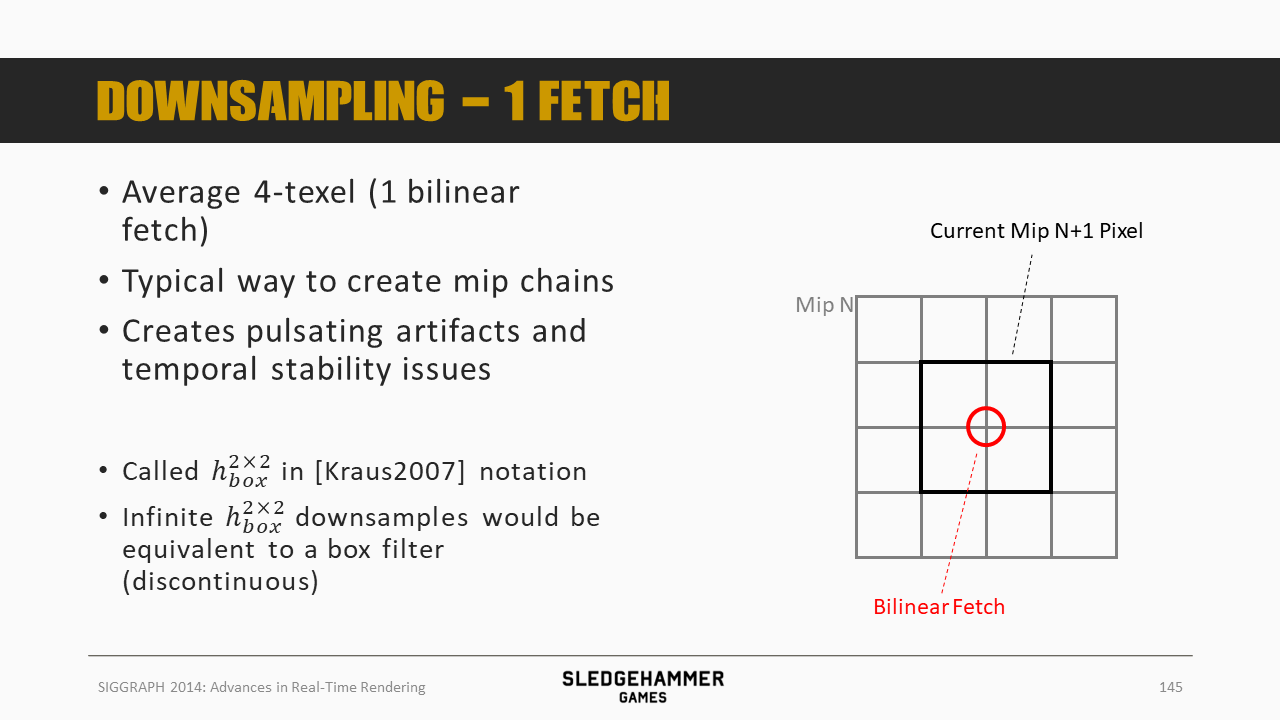
双线性单fetch会有很明显的瑕疵与稳定性问题
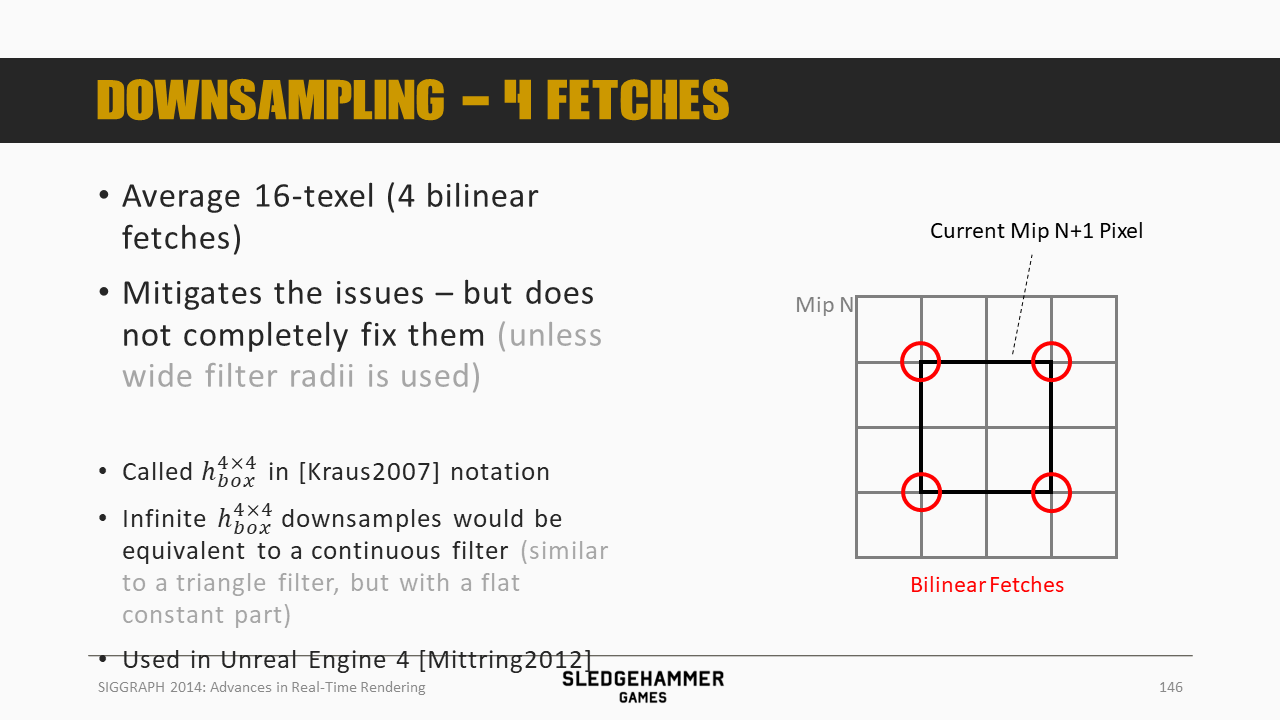
4fetch可以缓解问题,但是问题还依然存在

这里给了一个效果展示
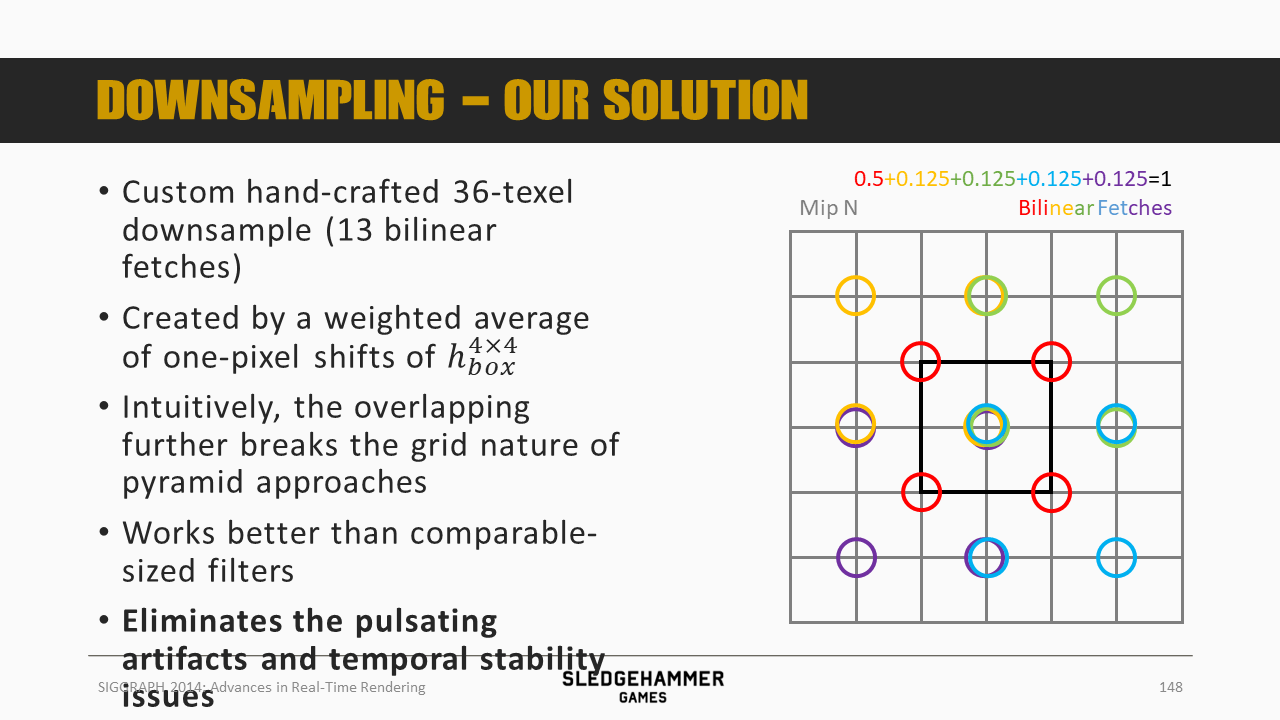
这里用的滤波kernel是一个人为设计的36个像素的下采样策略(通过13次双线性fetch),之后按照图示的颜色做加权平均。
从效果上来看,可以消除双线性滤波的瑕疵。
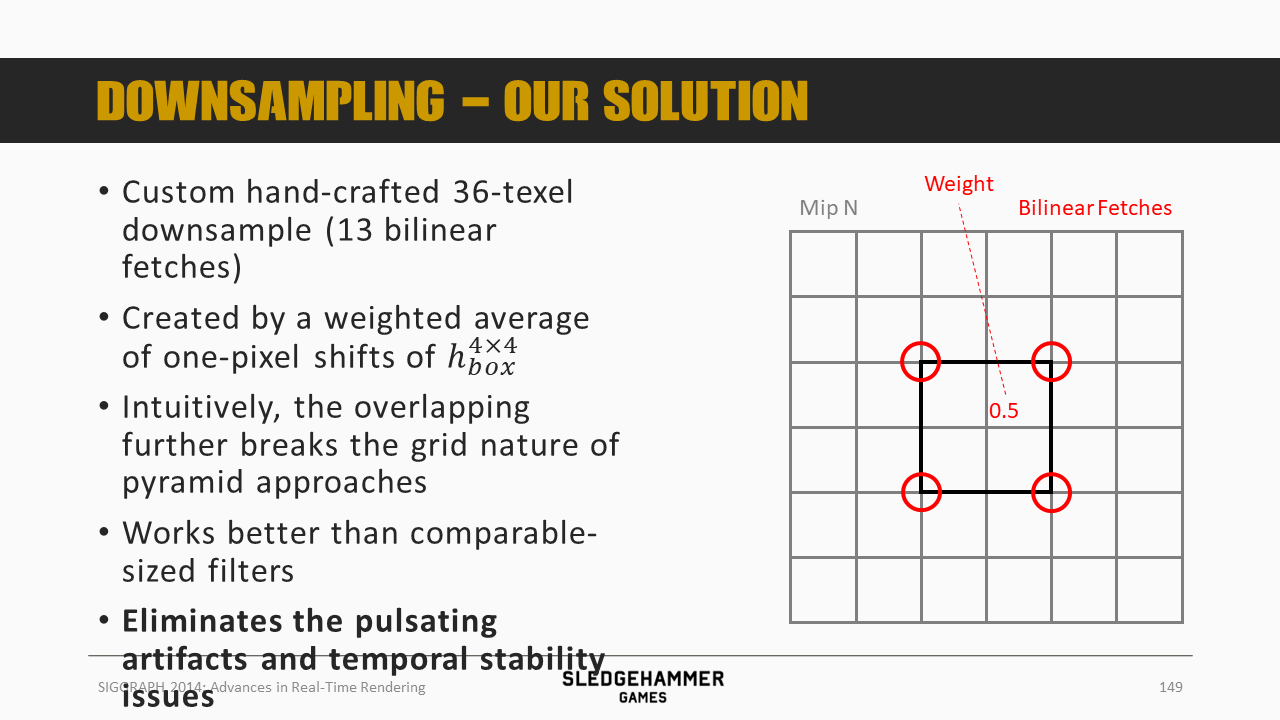
各个采样点正好位于多个像素的交界位置,使得可以通过硬件双线性混合来得到多个像素的混合数据。
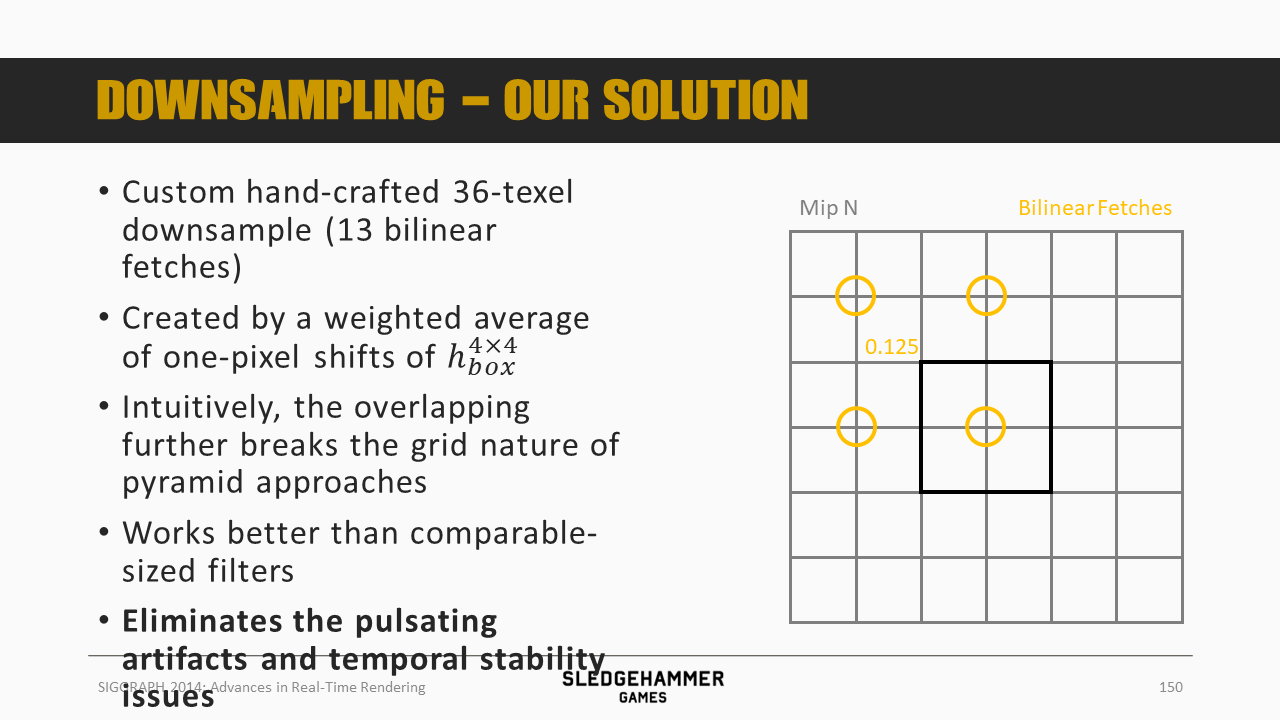
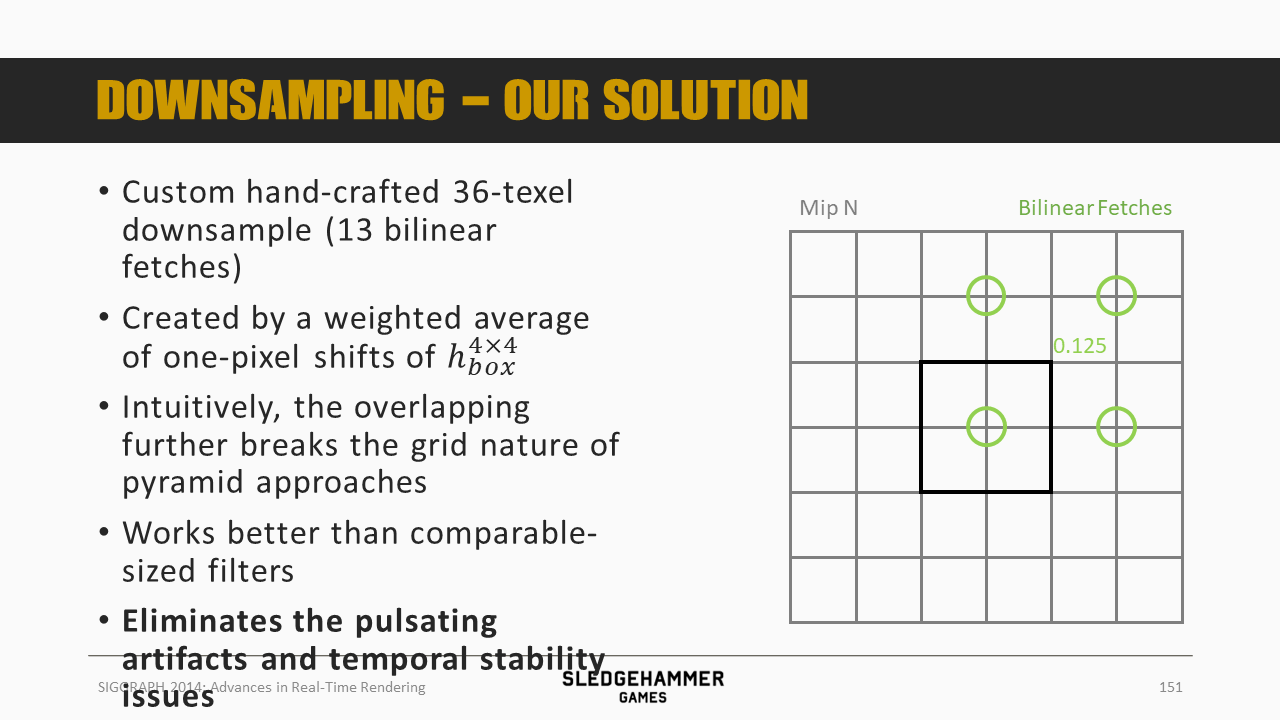
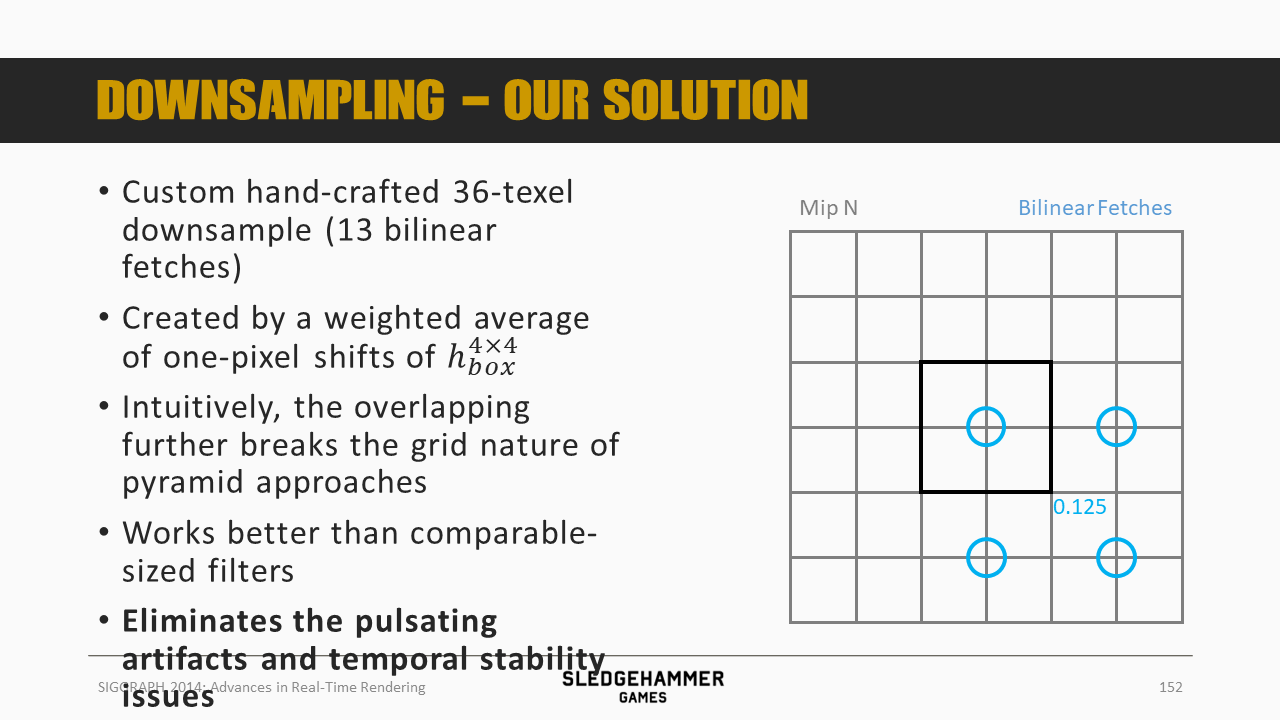
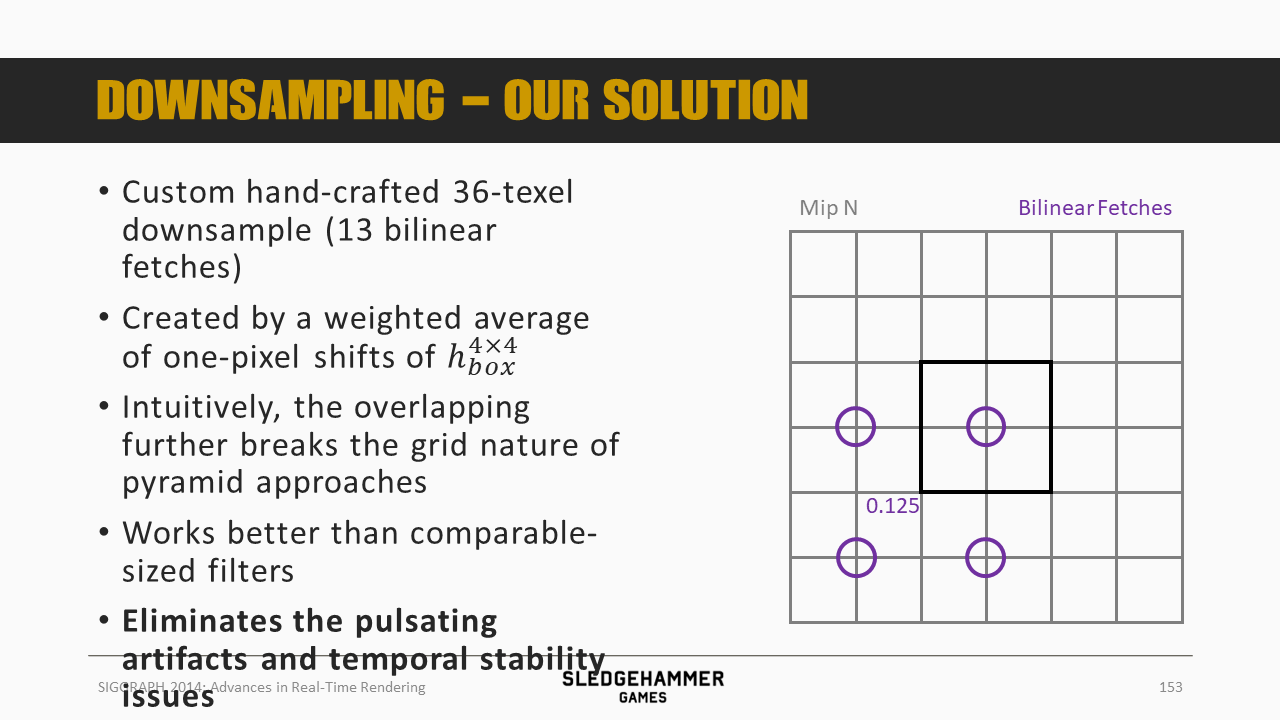
4个0.5的权重,4套0.125的权重,由于采样点有重复,因此总计只需要13次采样。

这里给出了这种方案的结果

上采样的时候,也有一些技巧:尽量避免跨级上采样,而是通过逐级上采样的方式来得到高分辨率的结果,之所以这种方式可以得到更好的结果,是因为这种采样方式等价于biquadratic b-spline(双二次B样条)滤波。

在做上采样的时候,还可以顺带完成跟之前mip的混合,从而节省一些计算的消耗。

上采样采用的是tent filter(3x3),并根据需要调整filter的滤波半径,这个filter在Kraus 2007中有说明,经过多次卷积后,将可以较好的逼近高斯滤波,不过比高斯滤波消耗低。

这是最后的效果

前面说到的时域稳定性问题中,上下采样导致的问题就解决了,接下来看看萤火表现问题。

萤火问题的原因是,HDR下由于下采样会导致高亮像素的闪烁。
Karis 2013中给出了一种优化方式,这里从mip0到mip1下采样的时候,也用了同样的策略

这里是效果。

在实施的过程中发现:
- 在平均计算之前,采用非线性的强度映射,会导致闪烁问题
- 在小尺寸物件按照其本身尺寸的step size对应的速度移动的时候,容易出现
- 虽然次像素运动(multi/supersampling)虽然能够解决这个问题,但是这种方法不是哪个地方都可以使用的
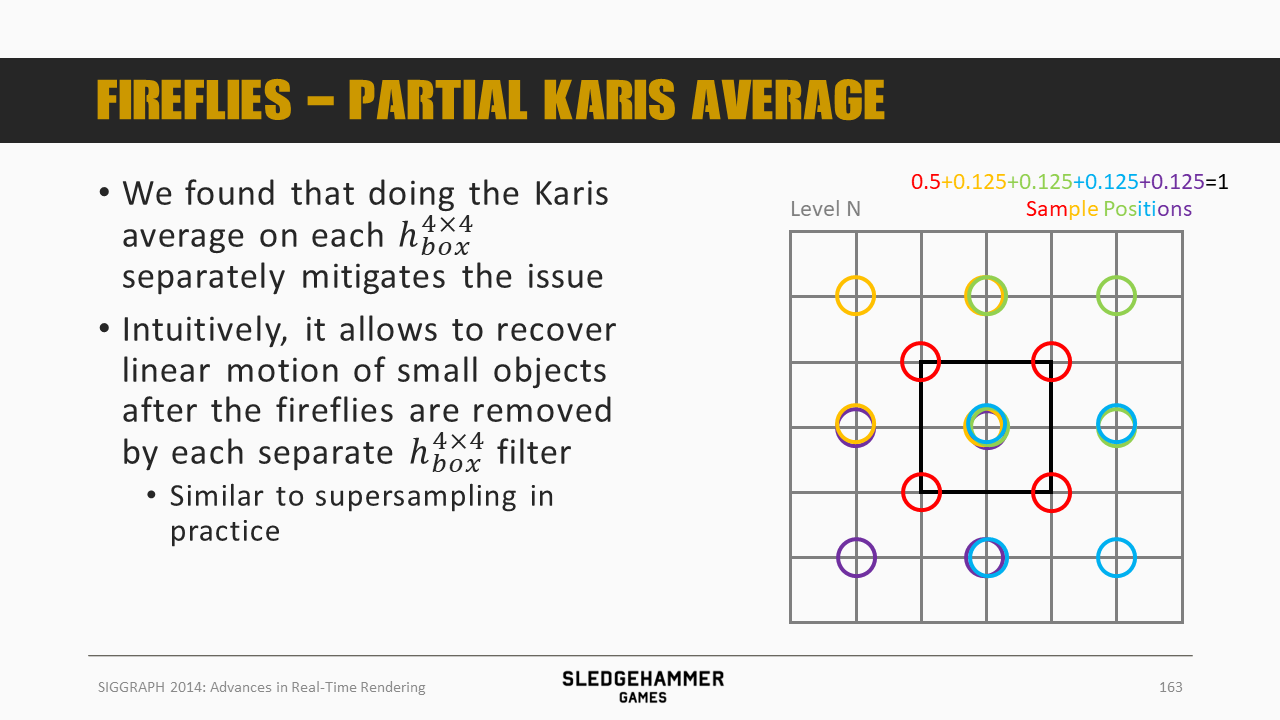
同时发现,在每个$h_{box}^{4x4}$上应用Karis的平均值算法之后,可以缓解这个问题。
表现上来看,通过这种方式可以在移除小物件的萤火效果的前提下,同时恢复其线性移动效果

针对萤火问题,最终的解决方案有两种:
- 全量应用:对前面下采样的每个fetch(总计13)中都应用Karis的平均算法
- 部分应用:以4个sample的block为单位应用平均算法。这是本文最后采用的方案
不论是哪种方法,这里的平均算法都只应用在从mip0到mip1的下采样的过程中

这里对两种方案的效果做了对比,看得出来,虽然都还在闪烁,但是本文的方法闪烁的频率相对低频。

这里对方案做一个总结:
- 通过小尺寸的2D kernel完成上下采样滤波
- 下采样使用13 tap的滤波方案
- 从mip 0到mip 1的下采样的时候,采用Karis的平均方案(部分)来缓解萤火问题
- 上采样使用9 tap的tent filter
- 逐级上采样
- 上采样的过程中,同时完成与此前已有mip数据的混合
- 下采样使用13 tap的滤波方案
- 最终的mips数目为6,格式为R11G11B10
参考
[1]. Next Generation Post Processing in Call of Duty: Advanced Warfare
[4]. A Reconstruction Filter for Plausible Motion Blur
[5]. A Fast and Stable Feature-Aware Motion Blur Filter
[6]. Real-time Stochastic Rasterization on Conventional GPU Architectures