
【Siggraph 2016】the devil is in the details
今天介绍的是idTech在Siggraph 2016分享的一些渲染相关的技巧,分享人是Tiago Sousa & Jean Geffroy,照例,这里对工作内容做一个总结:
- 因为工期紧张,因此开发的指导原则是KISS,即keep it simple stupid,也就是尽量的简洁
- 由于针对场景做了详细的规划与设计,因此最终版本里只有100个左右的母材质与350个PSO
- 整体帧率目标为60fps,其中GPU部分的耗时给出如下(前向渲染与延迟渲染之间的某种策略):
- shadow绘制耗时3ms,采用了cache策略
- 不透绘制耗时最多,约6.5ms
- 半透部分耗时1.5ms
- AO、反射、fog、composite等延迟后处理效果总计耗时2ms,这是管线中唯一的延迟部分,这部分的输入数据从forward pass中取,相对于传统的延迟渲染概念,这里的带宽消耗更低
- async post process耗时2.5ms
- Pre-Z耗时0.5ms
- 光照部分采用了clustered rendering来减少不必要的浪费,统一半透跟不透物件的绘制过程,不用单独处理以增加复杂度(流程与shader变体),cluster不仅仅用在了光源上,还用在了其他合适的应用,如reflection probe,贴花等
- 这里对如何判断某个froxel受哪些光源影响的策略做了优化,将屏幕空间的相交判断改成了Plane与AABB的测试,通过SIMD加速提升了计算效率
- 启用了VT,在控制消耗的基础上提升整体的效果,并做了如下的一系列优化策略:
- 对VT Page做了压缩以进一步降低消耗
- 采用了硬件sRGB来优化性能
- 优化了mipmap生成算法以降低高光锯齿问题等
- 优化了贴花的绘制过程,将之放到半透物件的光栅化过程中完成,与光照计算叠加在一起完成,采用的是类似光源光照过程的处理模式,据说可以高效的规避若干trouble case
- 先贴花的贴图混合逻辑,再光源的光照计算逻辑
- 不用单独的pass来渲染贴花,且因为不需要单独绘制贴花,也不用读取深度buffer,因此支持对半透物件叠加贴花效果
- 光照的一些设计:
- indirect diffuse部分,对于静态物体而言,会使用lightmap,动态物体则基于irradiance volume
- indirect specular部分的反射计算来自于三部分:环境光probe、SSR以及高光遮蔽
- 动态光源,只考虑直接光部分,做动态计算+shadow即可
- 寄存器压力会导致性能的显著下降,这里提供了一系列的优化建议
- 通过对特效的细致分析,提出了将特效粒子的分辨率与渲染的分辨率分割开来考虑的思想,并通过cache等策略进一步降低这里的渲染消耗
- 阴影的计算有如下的设计:
- 所有的shadowmap会被汇总到一张Atlas中,方便一次性绘制与取用,减少RT切换,增强合批
- 对满足条件的shadowmap做了cache处理,并会基于距离等各种因素动态调节各个光源应该分配的shadowmap分辨率,以有限的性能保障尽可能高的效果
- 如果cache的贴图没有动态物件叠加,就直接使用;有叠加,就做copy-paste-append处理
- 使用低模的proxy mesh替代高模的普通mesh来降低渲染消耗
- 方向光阴影用了CSM,两级之间的衔接处,通过dither做了平滑
- 基于下采样+高斯模糊的方式得到毛玻璃的mipmap结果,之后按照粗糙度进行取用
- 在渲染性能上,做了较多的debug工具来直观的展示性能压力区域
- shader复杂度(UE具备)
- 场景光源复杂度热力图(比性能热力图更为细分)
- 其他性能优化策略
- 根据GPU的负载,动态调节各个pass的分辨率,从而以尽可能低的成本得到尽可能无损的品质
- 在面片尺寸较大的区域,禁用VS参数缓存的延迟分配
- 谨慎使用Async Compute Shader以减少缓存命中率的破坏

本文的重点是渲染,且着重关注少数几个关键特性。
上图给出了id software的工作目标,包括帧率、分辨率、效果、美术同学工作效率等。
因为工期紧张,因此总体的工作原则是KISS(keep it simple stupid),即采用尽可能简洁的工作策略。
这里需要提到的一点是,由于提前做了精心设计,因此最终版本中只包含100个左右的unique shader,大约350个PSO(太省了)。
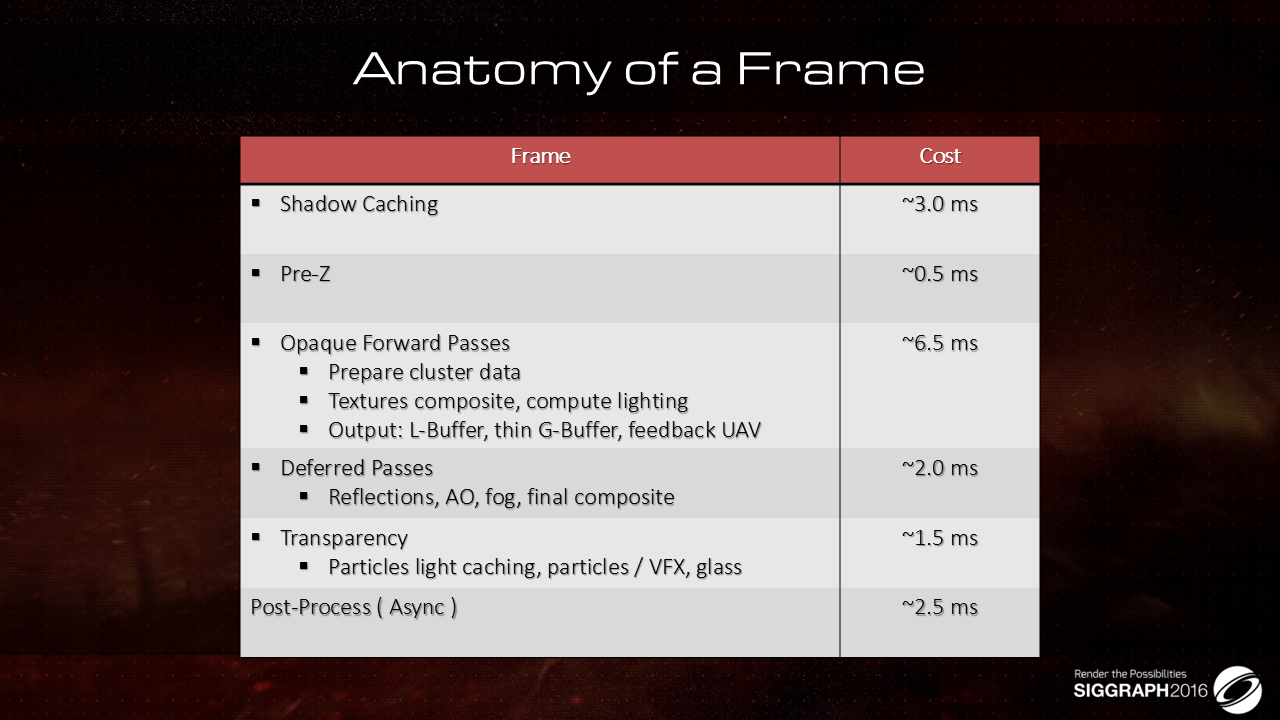
在60 fps的帧率下,各个pass的耗时统计:
- shadow部分启用了cache逻辑,耗时约3ms
- 耗时最高的为不透明部分的绘制,耗时约6.5ms
- 其他耗时则如上图所示,总体来说,耗时比较节省
这里有几点需要关注:
- 采用的既不是前向渲染,也不是延迟渲染管线,而是二者的混合,这种做法对于他们的项目来说,更容易达到性能与质量的平衡,所以,对于特定项目而言,定制才是最佳的路,虽然成本会更高
- 前向部分:
- 使用前向管线的好处是,可以收获一些前向管线独有的优势,比如可以开启MSAA,还有一些其他质量上的收益(接下来会说到)
- 前向管线也带来了一些约束,比如光照跟shading相关的数据都需要尽可能的提前准备好(目的是?),比如
- 光源相关的数据都需要提前准备好,方便在计算的时候进行索引
- 阴影也需要做一些处理(这个跟前向有什么关系?),比如shadow cache以及一些smart composite策略
- 延迟部分:只输出那些必要的特性(反射、高光遮蔽等)所需要的数据
- 不过上面的数据展示也只是一个示例,实际情况中后处理的消耗会随着情景的不同而有所不同
- 比如开启DOF的话,消耗会高一些等(在主机跟vulkan下,后处理是放到Async Compute中执行的)
- 比如部分情况下,特效会带来较高的overdraw,这个也会导致性能数据的波动

这里来介绍一下光照与shading的计算逻辑,总体思路是对下述两个talk中的方案的继承,实际上是clustered rendering策略,即基于三维的空间划分,得到的cluster中计算都会被哪些光源影响,从而降低光照计算的复杂度,具体参考milo的分享:
- “Clustered Deferred and Forward Shading”, Ola Olson et Al.
- “Practical Clustered Shading”, Emil Person
采用这种管线有如下的一些优势:
- 透明物件的绘制不用与不透明物件分割开来
- Depth相关的两点没看明白

这里介绍了clustered rendering中cluster的计算逻辑:
- 在CPU上基于Frustum的覆盖范围进行划分(没有考虑depth的range?),出于效率考虑,用了多线程计算,每个线程负责一个depth slice
- 采用的是person的方法,在对数划分的基础上对near/far plane做了处理,基于处理后的near/far plane做对数划分
- 采用对数划分,是因为近处精度要求高,所以需要分配更多预算
- 之后对cluster中的item做归类处理:
- item数据包含环境光probe、贴花以及光源(这三者都可以,也都应该做延迟计算)
- 归类的方式是将item的OBB(或frustum)做光栅化,之后与与当前cluster屏幕空间的xy以及depth bounds做比较

前面介绍的是常规做法,这里给出优化做法,即将OBB/Frustum光栅化到屏幕空间来判断是否相交的做法改成Plane与AABB的相交(包含)测试,基于这个做法,性能会有较大提升:
- 一个Cluster在Clip Space中就是一个AABB,而OBB跟Frustum可以分别转化为6个或者5个Plane
- 由于对于每个Plane的计算过程是相同的,因此可以使用SIMD来做运算的加速,从而提升计算性能

最终得到的cluster数据结构包含两个list:
- Offset list:这是一个3D数组,尺寸为[Grid Dim X,Grid Dim Y,Grid Dim Z],每个数组元素的长度为64bits
- 这个数组中存储的是每个cluster对应的数据在Item list中的起始位置
- Item list:这是一个一维数组,存储的是所有item的信息,item类型为光源、环境光probe以及贴花,其中
- 每个item包含24个bits,其中(感觉这里有优化空间,可以留出两位来表示item类型,剩余位数用于表示索引,不是更优吗?)
- 前面12位分配给光源,表示的是当前item对应的是哪一个光源(索引)
- 中间12位分配给贴花,表示的是当前item对应的是哪一个贴花(索引)
- 后面8位分配给环境光probe,表示的是当前item对应的是哪一个环境光probe(索引)
- 每个cluster最多包含256个item
- 最差情况下,每个cluster都有这么多数据,因此有上图中的最差情况下的该list的尺寸
- 每个item包含24个bits,其中(感觉这里有优化空间,可以留出两位来表示item类型,剩余位数用于表示索引,不是更优吗?)
- Grid分辨率目前采用的是16x8x24,还是比较低的
- GCN部分没看明白?

这里给出cluster debug view,其中红色表示有10个以上的volume overlapping,而绿色表示5个以下的volume overlapping,橙色则是二者之间的,文中介绍,虽然这里还有优化的空间,但是性能表现已经够用了,所以就不改了,直接发吧。。。

管线部分介绍完了,下面来看看如何给场景增加各种各样的细节:
- 依然开启了VT特性(Mega-Texture),不过相对于此前的引擎版本,做了一些升级
- VT覆盖了多种类型的数据贴图,从Albedo到Lightmap等:
- VT request的feedback buffer直接输出到final resolution(?)
- 通过Async Compute完成转码(什么情况下需要?),在数据不相关的时候,这个步骤消耗较高
- VT本身的缺陷还依然存在,比如
- 基于反馈的texture streaming就会带来贴图的popping闪现问题
- 只能应用于不透明物件
- Page边缘的瑕疵
- 滤波问题
- dependent lookup带来的额外消耗
- 高清贴图跟BC压缩贴图混用带来的异常等

贴花常见的策略如mesh decal或者延迟decal,在trouble case的处理上会比较耗时间(没有具体说明是哪些trouble case?),这里给的策略是将贴花嵌入到正常物件绘制的光栅化逻辑中。
上下文没有给出具体的实现说明,根据已有的信息推断实现过程,可能的策略为:
- 通过cluster统计出各个cell关联的贴花列表
- 在物件光栅化的时候,仿造lighting计算,对贴花数据做投影采样
- 为了避免单个物件在遍历多个贴花时的消耗,这里将贴花放到VT(8k x 8k分辨率,BC7压缩模式)中,从而可以在一个pass中完成多个贴花的遍历
这种策略可以保障在depth不连贯的区域以及跨多个物件的情况下,都能有正确的表现,除此之外,还有一些前面的方法所不具备的优点:
- 可以很容易实现贴花法线跟依附物法线的混合
- 支持mipmapping与各向异性效果
- 支持半透贴花
- 支持多层贴花的自定义排序
- 不会因为贴花带来drawcall的新增

贴花实现的一些细节介绍:
- 哪些物件需要受贴花影响是按照上述的box projected的计算逻辑给出的,被该box覆盖的物件的部分就需要被影响
- 对于每个贴花,在做贴图采样的时候,还需要考虑缩放跟偏移,不过由于需要依赖于计算得到的uv来做贴花的可见性clip,因此这部分没有直接放到box projection的矩阵运算中

关于贴花的其他一些信息:
- 贴花的布置是美术同学手动完成的,包括每个贴花的配置参数
- 每一帧可见的贴花的数目(还是贴图分辨率?)限制在4k,通常是1k及以下
- 美术同学会需要设计贴花的可见距离以实现消耗的lod处理,这个距离会跟画质等级有关系
- 场景贴花只对静态不可形变的物体生效

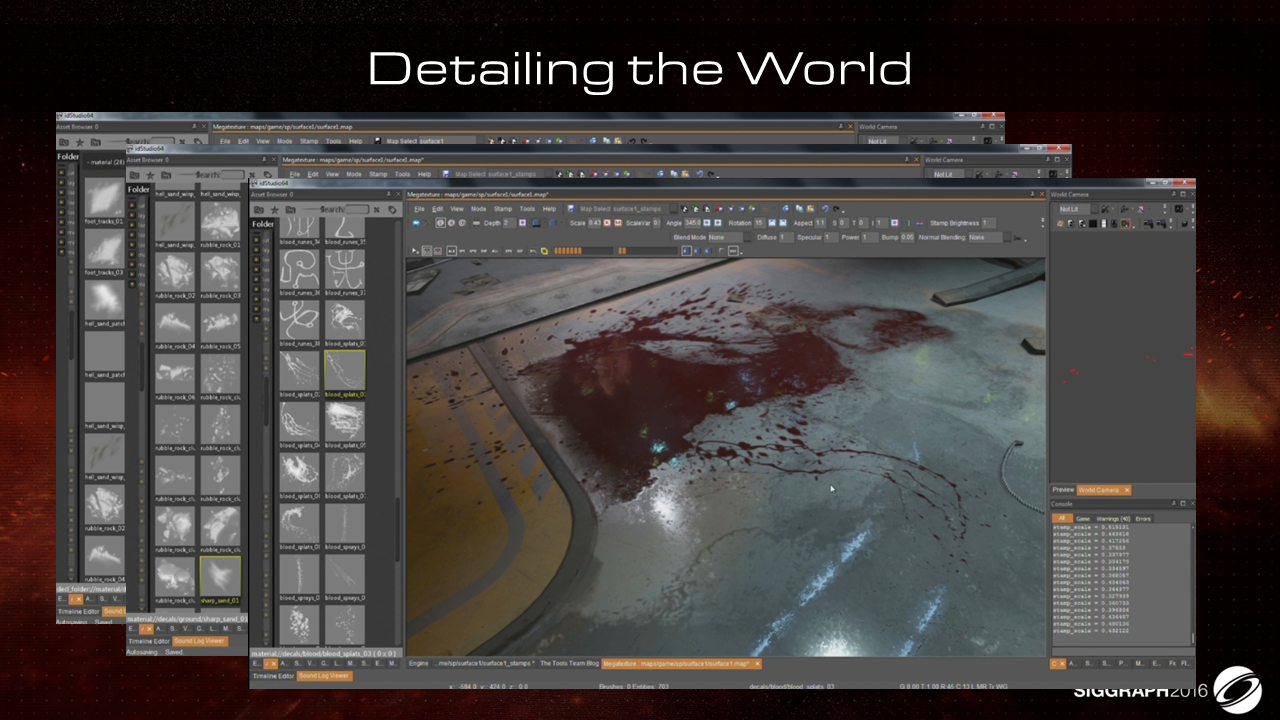
上面两图展示了贴花的实际效果。
有的时候,会需要通过多层贴花叠加来提供更为真实的细节,这里当然会有overdraw的消耗,通常这个消耗也会跟屏幕覆盖率有关系。
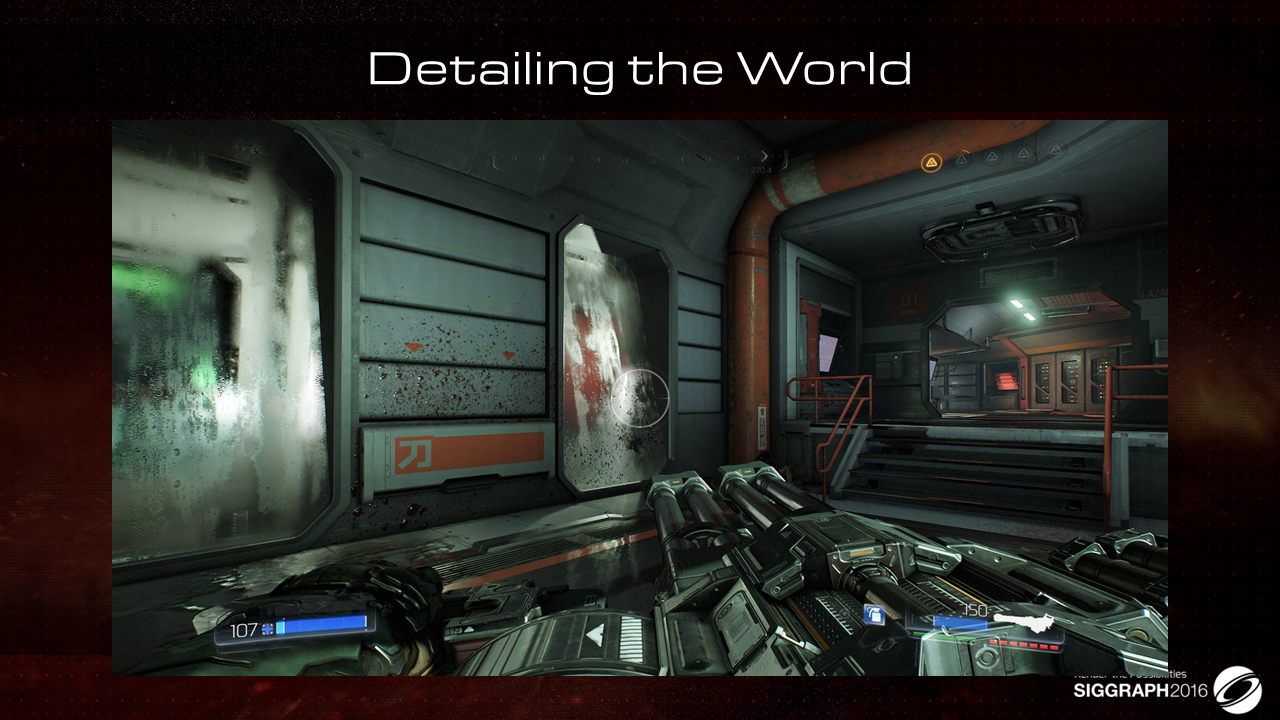
针对玻璃的各种效果,通常也是通过贴花来完成,如玻璃上的薄雾、水雾凝结、血渍等

接下来介绍光照部分,有如下的一些关键要点:
- 针对不同的物件(透明、不透等),采用一条统一的光照路径(同样的计算逻辑)
- 不存在shader变体焦虑
- 所有静态物体都走同一条shader计算路径
- 更好的避免渲染时的上下文切换
- 针对不同的光照分量,这里总结如下
- indirect diffuse部分,对于静态物体而言,会使用lightmap,动态物体则基于irradiance volume(PRT?)
- indirect specular部分的反射计算来自于三部分:环境光probe、SSR以及高光遮蔽
- 动态光源,只考虑直接光部分,做动态计算+shadow即可
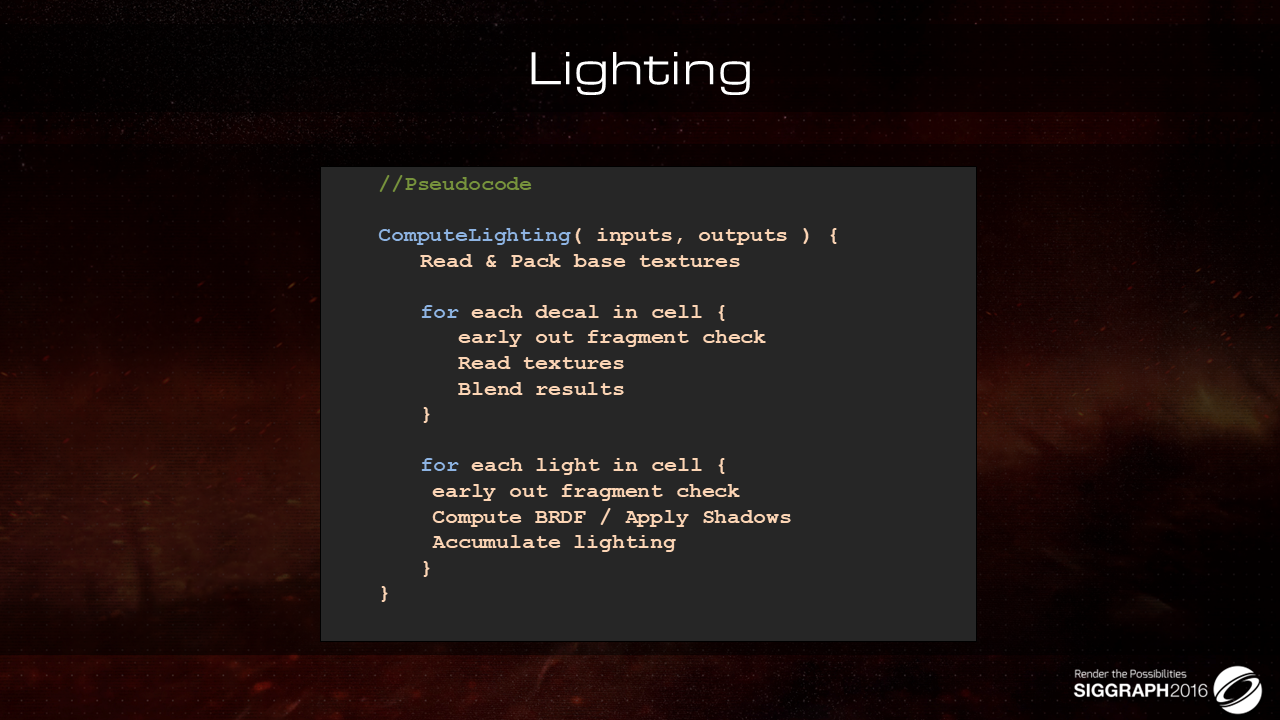
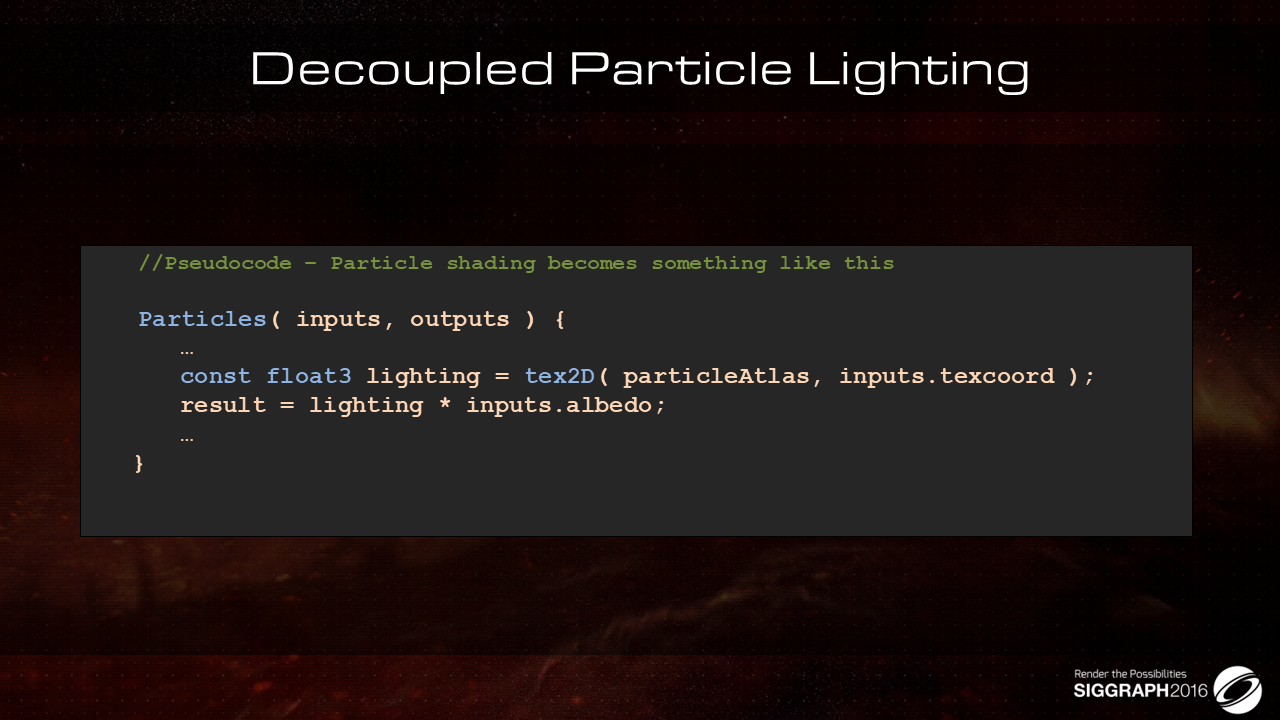
考虑贴花跟光照部分,每个物体的渲染shader伪代码给出如上:
- 遍历贴花,基于可见性判断是否跳出贴花相关计算,不跳出则执行贴图的读取与混合
- 遍历光源,判断是否受该光源影响,受影响则计算BRDF,叠加阴影并做光照的累加

来看下阴影部分的实现细节:
- 阴影贴图合并成了Atlas
- 对于符合条件的阴影做了Cache处理,针对不同平台,在分辨率上以及数据格式上做了差异化处理
- 对于同一盏光源的阴影贴图,会基于距离
- 调整分辨率(甚至格式?)
- 调整更新策略
- 用了proxy mesh代替原始mesh来生成阴影
- 对于光源不变的情况来说,这里会根据具体情况来做区别处理
- 首先需要cache静态物件
- 其次,针对参与投影的物件是否会有更新来做不同处理
- 有更新的话,需要在cache部分上叠加动态的
- 无更新那就直接使用cache贴图(不做copy & draw)
- 将上述方案的控制参数暴露给美术同学

- 除了shadowmap合并成atlas之外,每盏光源对应的shadow绘制的投影矩阵也需要packed到一起,之后根据光源的索引进行取用
- 为了降低VGPR(寄存器)压力,这里将所有类型光源(包括方向光)的PCF阴影计算逻辑统一成一套代码(不用为不同类型编写单独的实现逻辑,也就不用占据更多的寄存器?)
- 方向光的特殊处理
- 相邻等级之间会通过dither做过渡(UE没有做这个处理)
- 只做一次采样,不做两次采样+混合,可以降低消耗
- 尝试了VSM以及相关变种,发现存在各种瑕疵,或许对于前向管线而言更为合适

针对FPS游戏,在手臂处开启跟关闭自阴影会有较大区别,这个主要是通过一张单独的shadowmap来实现支持,在主机(性能吃紧)上会关闭这个特性。

clustered 管线下,光照计算逻辑尤其需要关注寄存器压力,这里有一些使用tips:
- 对于有较长生命周期的向量数据,可以考虑转成标量,同时调整数据格式
- 尽量缩短寄存器的常驻时间
- 减少嵌套循环,从而降低最差情况下的寄存器占用
- 减少分支(多分支寄存器占用叠加,如果是动态分支就没事了吧?)
- PS4上只有56个寄存器,PC上会高一些
- 对于不同的GPU品牌,使用倾向也有所不同,比如
- 英伟达芯片倾向于使用UBO/ConstantBuffer等
- AMD则倾向于SSBO/UAV

毛玻璃的实现逻辑:
- 先将Scene Color做几次下采样,得到一个mipmap,最高分辨率是1/2全屏分辨率
- 通过高斯模糊来得到下采样数据
- 之后在绘制各个毛玻璃物件的时候,会基于物件表面的光滑度对采样时的mipmap层级进行调制
- 出于性能考虑,折射transfer(这是啥?)最多只能有两个(?)
- 为了实现表面细节的区别,这里会通过贴花来为不同位置赋予不同的参数
- 不同光滑度、形状的玻璃叠加不同的贴花,通过乘法原则实现更丰富的表现

针对特效的光照计算,有几种方法,从顶点光照、顶点+Tessellation光照、像素光照以及混合分辨率光照,都有各自的问题。

基于观察发现粒子所接受的光照变化相对低频,且整个粒子面片上的光照变化也相对低频,因此可以考虑将粒子本身的渲染分辨率与其光照计算的频率解耦开来。
简单来说,就是基于粒子到相机的距离或者屏占比,为不同类型的粒子指定不同分辨率的quad(对齐粒子朝向),对quad上的每个元素进行光照计算,之后在渲染粒子的时候,安超bicubic插值逻辑对quad上的光照结果进行取用。
这里的性能收益来自两方面:
- quad的光照计算结果可以cache,比如粒子本身的位置跟光源数据都无变化时,此时结果就不用更新
- quad的光照计算频率可以独立于粒子本身在屏幕中的像素,不受屏幕分辨率的影响(其实还是受一点?)
这里的代价为:
- 渲染粒子之前,需要先绘制lighting quads,这里会有一次RT切换的成本
- quads的绘制可以通过instancing完成,写入到一张Atlas中,增加一个额外的DP
- 绘制粒子的时候,会需要多一次额外的采样
- 为了提升缓存的命中率,相邻的粒子对应的quad应该要放在空间相邻的位置上
光照quad的结果最后会放到一张atlas中,避免渲染时DP被打断

- Atlas的尺寸会跟随平台以及quality switch而调整,格式是R11G11B10。
- 前面说了,为了提升缓存命中率,出于同一个特效中的粒子,对应的quads应该要放在空间相邻的区域,这里就为每个特效划分了一块区域,虽然有一点浪费,但是表现(性能)还是不错,所以就没有细究
- 前面整理的新增消耗大多数情况下0.1ms就能搞定,复杂情况会去到1ms,但是相对于带来的收益而言,这部分的消耗大约只有1/10
- 此外,这部分工作可以借用Async Compute来实现,可以将这部分消耗并行去掉

结果看着还挺不错的,就不知道上面说的逐粒子的光照quad指的是每个粒子面片,还是一整个特效?从需求层面来看,似乎是可以考虑将quad做成针对单个特效的billboard,比如上图中的云雾就可以只用一个quad?可能还得看下原始特效是如何渲染(光照)的,先从保守的方案尝试,再看要不要到这么激进。

Doom的后处理技术在Siggraph 2013中就做过介绍,所以这里就没有过多赘述,后面有需要再去翻翻。

GCN提供了一个叫做scalar unit的特性,这个特性可以用于在一个wavefront中实现计算结果的共享。
相对于基于vector memory操作来获取数据,基于scalar unit获取数据有如下的一些好处:
- 一次性可以获取的数据会更多(64 B VS 16 B)
- 数据可以存储在SGPR中,从而降低shader的VGPR的消耗数目
- 由于数据是标量存储的,因此在执行分支计算的时候,就不用担心多个线程执行的逻辑不一致的问题,也就是说,对于每个像素(线程)而言,就不用两个分支都执行,从而加速整体的执行效率
这里需要注意的是,只有当scalar unit执行的时主路径,而非某个在运行时根据条件动态开关的动态路径的时候,才能够节省VGPR的消耗,如果多条路径都要执行,那VGPR大概率还是会被占用,优化也就没了。
下面看看这个特性是如何使用的

这是一个debug视图,有点类似于性能分析中常见的热力图(可以考虑在热力图的框架上增加类似的debug信息),其中:
- 蓝色表示wavefront中多个线程对应的光源、贴花等数据完全相同的区域,覆盖了场景的绝大部分区域,表示大部分区域下wavefront的现成执行一致性都还比较高,缓存命中率高
- 绿色表示wavefront中多个线程只受一盏光源影响的区域,这个符合cluster cell的范围设定,即屏幕空间处于一个wavefront中的线程(像素),其对应的光源列表基本上是相同的,从而可以较好的实现wavefront之间的数据共享
- 红色部分表示wavefront中多个线程之间需要获取的光源数据有所区别的区域,具体一点则是有5个以上的元素(光源、贴花等)并不是每个线程都需要用到(即是局部共享)。这个覆盖范围也不小,

基于前面的观察有上述的结论,即大部分情况下,一个wavefront中各个线程对应的元素基本上都是共享的,因此:
- 以线程为单位来访问cell数据就会有点浪费(类似于逻辑是应该放VS还是PS)
- 可以考虑将这部分共享的数据抽取出来,方便通过标量计算操作获取(以降低VGPR压力?)

首先,先回顾一下设置。Cluster的每个Cell都存储了一个灯光和贴花偏移的排序列表。
根据算法,wavefront中的每个线程都有可能访问不同的Cell,因此需要使得各个线程能够独立的对这些排序数组进行遍历计算。
具体而言,就是将遍历过程做成串行。举个例子,有三个线程需要分别独立遍历 [A、B、C]、[B、C、E] 和 [A、C、D、E],这时我们可以串行迭代 [A、B、C、D、E],从而使得各个线程访问的数据是一致的。
注意,虽然这种做法会导致循环迭代次数变多,但获取数据的速度会明显加快,同时在这个过程中,还有可能节省寄存器的消耗。
再具体一点:
- 每个线程会需要在待遍历的灯光/贴花 ID数组中维护一个索引。
- 计算所有线程中需要访问的最小的元素 ID(结合使用 swizzle 和 readlane 指令),从而保证各个线程访问的起始灯光/贴花 ID 是相同的
- 在实际计算的时候,通过scalar unit遍历数组,并完成相关元素的计算。
- 完成后,关联此元素的线程(难道不是wavefront中的所有线程?)会递增本地索引,并处理下一个元素。
通过这种方式,可以保证所有元素都能按顺序处理一次(不会带来浪费吗?难道获取数据的加速能够掩盖这部分损失?)。

针对前面的实现框架,这里还打了两个补丁:
- 只访问cell数据的wavefront会走单独的快速计算逻辑,跳过重度的最小ID计算逻辑,改用一些简单计算
- 串行处理能提速的前提是各个线程的局部一致性较好,对于各个线程访问数据较为杂乱的情况,会是一个负优化,不透明物件的渲染基本上还好,不用特别处理,但是对于部分应用场景如粒子照明atlas生成环节则需要关闭该功能
上图给了具体的性能优化表现,可以从原始的8.9毫秒的消耗降低到6.2ms(同时还能够减少寄存器的占用,提升可并行执行的wavefront的数目)。

这里还做了一个动态调整分辨率的计算策略,会根据GPU的负载来调整以保障流畅性:
- 通过降低viewport的尺寸来实现,需要修改实现代码(只能在OpenGL上执行?)
- TAA可以从不同分辨率上拿到数据,效果不咋受影响
- 通过Async Compute来完成上采样

基于如下的两个观察:
- 阴影、深度渲染pass很少使用compute shader
- 不透明渲染pass在compute shader上的占用也不高
因此可以考虑在这些pass执行的时候,并行叠加后处理pass(通常用compute shader完成,借用async compute提升渲染效率):
- 后处理、AA、上采样、UI集成可以放到compute queue中
- GUI的绘制还是在GFX queue中
- 上述第N帧的compute queue的计算逻辑将会与第N+1帧的shadow/depth/opaque绘制逻辑并行
- 如果可以的话,还可以通过compute queue完成present(?)以减少延迟

最后给一些性能调优的建议:
- 通过对细节、参数的调校,DOOM在部分场景下优化了1.5ms的消耗
- 在单位面片像素数目占比过高的静态物件绘制的时候,禁用掉VS参数缓存的延迟分配(vertex shader parameter cache late allocation,)功能会有性能提升
- Async Compute的引入会加重缓存的破坏,因此限制这部分compute的使用频率与负担有助于提升性能
VS参数缓存的延迟分配解释
背景
在现代图形渲染管线中,顶点着色器(Vertex Shader)负责处理每个顶点的数据。这些数据通常包括顶点位置、颜色、法线、纹理坐标等。为了提高渲染性能,GPU会使用某种形式的缓存机制来存储和传递这些数据。
参数缓存(Parameter Cache)
参数缓存是GPU用来暂时存储顶点着色器所需数据的一种方式。传统上,参数缓存会在顶点着色器执行之前分配和准备好,以便在着色过程中进行快速访问。然而,这种方法在处理复杂场景或动态变化的内容时,可能会导致效率低下,尤其是在缓存命中率低的情况下。
延迟分配(Late Allocation)
Late Allocation的思想是推迟参数缓存的分配时机。与其在顶点着色器开始执行之前就分配缓存,不如等到确定需要这些数据时才进行分配。这有几个潜在优点:
- 减少浪费:只有在需要数据时才分配缓存,避免了不必要的内存占用。
- 提高缓存利用率:通过延迟分配,可以更智能地管理缓存,提升命中率和效率。
- 灵活性:在更动态的场景下,延迟分配能够更好应对不断变化的数据需求。

最后介绍一下寄存器分配的约束:
- 在大多数情况下应该控制Shader所使用的寄存器的最大数目。
- 不必严格以 256 的除数为目标,部分情况下换其他的数值可能结果更好
- Pixel Shader并不是完全独立执行的,需要考虑并发的其他shader,async Compute、vertex shader等都会占用寄存器
- 在 Doom 中
- 不透明 PS 分配了 56 个 VGPR, VS 分配了 24 个 VGPR:在整体上可以有更多的wavefront并行执行
- 相对而言,如果激进的分配 64个VGPR 给PS,当我们有 4 个 PS wavefront在执行的时候,就没有办法并行运行其他的wavefront了


还有一些其他待优化的点,项目侧:
- Texture quality
- Global illumination
- Overall detail
- Workflows等
硬件、驱动侧:etc
- Profiling tools in general are about 1 decade behind what we have on consoles
- AMD: please fix your shader compiler
- Can we get Barycentric coordinates on all HW exposed?
- Sampler Rect
- Better filtering






cubemap的分辨率是128,BC6H

期望结合两种管线的优点:
- Performance & Screen Space Approx. from Deferred
- Simplicity & unified from Forward.
对于RT,不希望太重度,对于GCN/主机都不太友好(移动端也是)
Main Lighting Buffer的格式是: R11G11B10F
最终的AO、反射效果是多种方案的结合:
- SSR
- 环境反射cubemap
- AO/SO
- 雾效
参考
[1]. Siggraph 2016 talk : The devil is in the details