
【GDC 2014】 Deferred Normalized Irradiance Probes - Assassin's Creed 4
本文分享的是刺客信条4(黑旗)在GDC 2014上介绍到的全局光方案,分享者是育碧蒙特利尔的图程Bartlomiej Wronski,照例,这里对工作内容做一个总结:

刺客信条4是一款历史动作冒险视频游戏,背景有如下几个关键词:
- 17世纪,海盗的黄金时代,
- 加勒比海地区,广阔的开放世界
虽然是刺客信条游戏系列的第六部,但是新的背景和历史时期也提出了几个新的挑战:
- 多种环境类型
- 小岛和无人海滩
- 人口稠密的城市
- 深邃的丛林
- 加勒比海的开放世界
- 动态变化和不可预测的热带天气和各种大气现象——暴雨、雾、雾、上帝射线
- 非常少的人工光源,需要仅使用自然光来实现有趣和复杂的照明
- 针对六个不同的硬件平台发行,包括下一代游戏机——微软Xbox One和索尼PlayStation 4。
接下来,将介绍该作是如何通过不同的策略以实现美术效果在所有目标平台之间的一致。

接下来会重点介绍如下四个方面的内容:
- 全局光算法:
- 基于Deferred Normalized Irradiance Probe实现
- 这是一种本来用于适配下一代硬件的动态光照技术,不过这里将之用到了当代硬件上,并得到了不错的表现
- 体积雾:这里开发了一种新的算法,利用Compute Shader和3D贴图来模拟传播介质中的光传输以及各种光散射和大气现象
- 屏幕空间反射:会介绍这里是如何针对PS4 / Xbox One是如何优化的
- Xbox One和PlayStation 4上采用的GCN GPU架构。

先来看看GI

过往AC系列中,GI效果比较差,太阳光方向基本上不会变化,在不同地区的亮度也没有太大的差别(这是因为之前采用的渲染管线并不支持过高的dynamic range,因此对于阴暗的区域,不太适合做过多的调整),同样,不同区域的颜色差别也不大。
因此,AC4这里的一个重要目标就是要优化GI的表现,在这个过程中,尝试了多种实时的GI方案,这些方案要么性能差,要么效果差,无法复现哈瓦那、金斯敦或拿骚等城镇小巷中的复杂光照表现。
性能目标:
- GPU耗时低于1ms
- 显存占用小于1MB
动态的GI效果是难以保证了,因此基于烘焙的方案就成为了必选项,但是如何将烘焙方案与动态TOD、天气结合起来,就成为了新的挑战。

下面来介绍这里采用的Deferred Normalized Irradiance Probes方案(简称DNIP,下同)。
经过观察发现,在晴朗天气下,通常大部分感知到的间接光照来自主光源,而基于这个观察,这里做了如下的设计:
- 基于AC4的引擎能力,可以将来自天空的间接光与主光源的反射光分离出来
- 并通过World AO以及屏幕空间AO来提供间接光阴影信息
- 天气的类型差别不会影响主光源的方向,只会调节其颜色与强度
- 光源的光强与颜色可以从Light Transfer Function中提取出来(从而可以将之与天气进行联动?)
- 对于那些仅需要考虑单次漫反射的GI数据,可以基于Albedo、Normal以及Shadow数据等参数提前做一个离线的计算来拿到一些数据,从而降低运行时的计算消耗

离线预计算的数据会按照上图所示的格式进行存储:
- 一个probe需要包含一个按照RGB三通道存储的归一化irradiance(每个通道8bit?)数据
- 存储8套数据来实现日夜变化
- 需要存储面向四个不同基向量的数据(基向量复用FC3的策略)
- probe按照grid均匀分布,间隔2m
- 高度上不做多层分布,仅根据场景的高度布设一层,这个跟FC3的策略也是一致的

整个算法可以分成离线跟运行时两部分。
- 离线部分:
- 在GPU上,会通过cubemap capture与卷积来得到四个基向量的irradiance数据
- 由于Albedo跟Normal是恒定的,只有阴影数据会跟随时间变化,所以GPU的烘焙过程还是比较高效的
- 烘焙以64x64m为单位进行,每轮烘焙用到的高精shadowmap不用重复分配,可以在下一轮复用
- 由于probe只保留一层,因此结果可以存储到2D贴图中,之后会经过压缩后保存
- 运行时部分:
- 由于需要做TOD变化,因此运行时需要对两套数据进行采样,并完成混合处理,之后基于天气数据做De-normalize,结果作为主光源的final irradiance
- 由于这里会假设GI信息仅在NavMesh附近(不管是高度附近还是水平附近)才有效,所以得到的结果还会根据NavMesh的信息,按照高度做一个blend
- 将上一步计算得到的主光源的间接光照,与天光的间接光以及AO(间接光阴影)结合,得到最终的GI结果

这是之前AC3的光照结果(没有叠加AO,仅间接光),当时仅采用了Ambient Cube来提供GI数据,这个画面的光照对应的是晚上7~8点,由于太阳角度低,因此这个区域完全处于阴影中。
可以看到,效果缺失了法线贴图的变化,显得很平。画面也比较暗,但是如果提高亮度,就会使得画面变得更平。。。

这是新方案的表现,光照结果会跟随光照方向而变化,不同法线效果下的光照表现也有了区别(观察地表光照)。
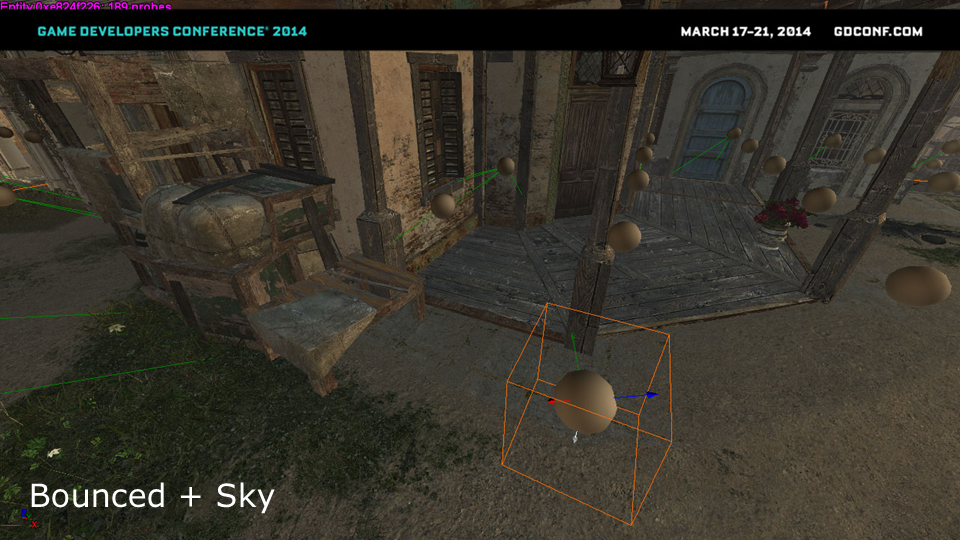
将主光源反弹的间接光(bounced)与用lighting cube表达的天光相结合之后,光照的变化就变得更丰富了,也能感受到物体表面的法线变化效果。

之后,应用了世界环境光遮蔽(World AO)和屏幕空间环境光遮蔽(SSAO)之后,就得到了上述效果。
World AO技术细节,请参阅Jean-Francois St-Amour在GDC 2013上的演讲《Rendering of Assassin’s Creed 3》。
在上图中,还展示了多个probe的布局(每2米放置一个):
- probe基于导航网格自动放置
- 完成防止后,会建立相邻probe的可用关系——绿色线条表示因碰撞而缺失的probe,有了这个关系,在后续的计算与插值中,就能够较好的规避异常数据使用导致的问题了。
最后,上图还展示了irradiance向量基,用的是《孤岛惊魂3》中的向量基,即三个指向上方的向量(类似《半条命2》的基准),以及额外的第四个环绕(wrap around)向量,负责处理从地面反弹的光照。

跟最早基于ambient cube的方案(AC3)的效果做比对
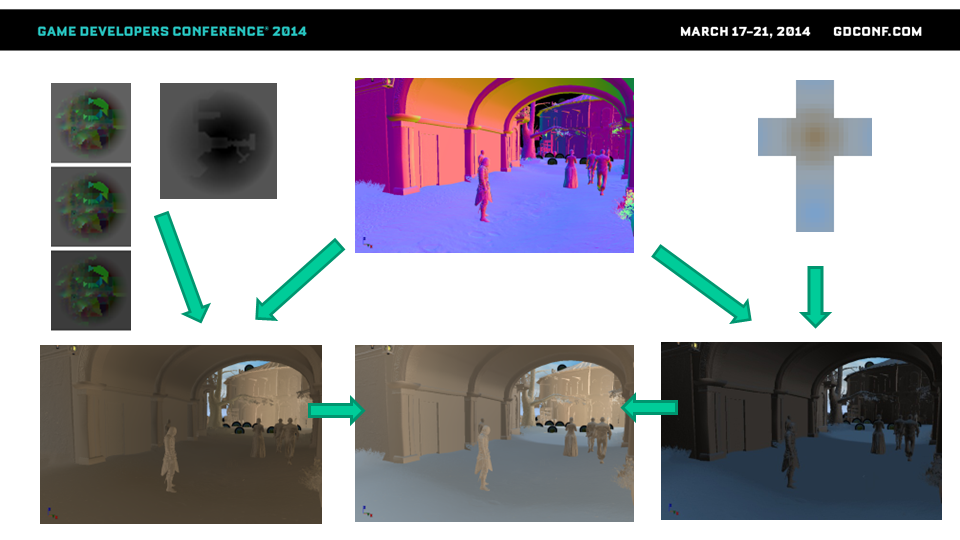
场景光照结果可以拆分成两个部分:
- 幻灯片右侧:天空光照——环境cubemap结合法线+世界环境遮蔽数据(模拟高层建筑及其他”大型”几何特征的遮蔽效果)
- 幻灯片左侧:间接光照:
- 3张irradiance贴图(RGBA通道对应于四个4个基向量,每个向量包含三个数值,对应于三张贴图)
- 包含irradiance光源probe高度信息的World Height数据
- 根据距离和高度的不匹配程度逐渐渐变淡化
- 中央区域:合成环境光(未使用SSAO)

最后做一下总结与Benchmark介绍。
性能开销:
- PS3 & X360平台在未启用模板标记优化(天空、海洋)时,全屏渲染耗时1.2ms
- 当与阴影遮罩计算合并为单次渲染时,总耗时约1.8ms
- 次世代主机及PC平台上,反弹光计算相比同步处理的阴影遮罩可忽略不计
- 内存占用:加载玩家周围25个区域数据,每个区域存储8个时段、4个方向的16x16 Probe
- 总计消耗25张48x128的RGBA纹理 = 600KB显存(48?)
- 曾考虑采用DXT5压缩或仅流式加载2个时段数据,但因开销几乎可忽略而未实施
- CPU性能:
- CPU端需要执行纹理选择、混合绘制调用及计算重叠纹理视口等操作
- 还需解压存储在RAM中的游戏可用地形高度数据。虽通过向量指令大幅优化,开销仍不可忽视
- 完整更新耗时约0.6ms。所幸得益于支持纹素对齐,我们可仅在需要时更新高度数据
- Probe数量:
- 采用网格对齐的暴力放置法时,典型游戏世界约含110,000个探针
- 改用导航网格仅放置可到达区域后,数量降至30,000个
- 全局烘焙时间:
- 在单台GTX 680设备上,完整世界及8个时段的烘焙耗时约8分钟,因此无需分布式处理,技术美术总监和灯光师可随时触发
- 还增加了单Probe重烘焙功能,并在编辑器中实现后台持续烘焙(viewport内探针会实时更新,几乎无性能影响)

下面看下体积雾的相关内容。
我们称之为“体积雾”的技术,实际上是对多种不同大气现象的模拟:
- 雾、薄雾、霾
- “上帝之光”
- 光束
- 含尘/潮湿的空气
- 体积阴影
但所有这些现象都源于同一个物理原理——光的入射与出射散射!
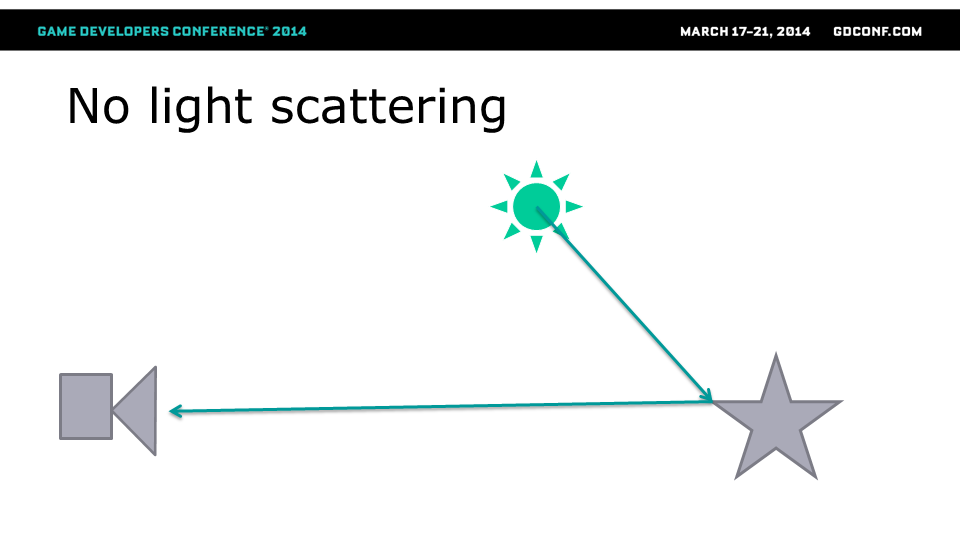
先看看无光散射/非参与传输介质:
- 先假设传输介质的行为类似于真空——在物体之间的光路上没有辐射的损失或增益。
- 典型的渲染场景——来自光源的光线根据表面BRDF函数从一个物体反射到另一个物体,最终到达相机/眼睛。
- 最简单的情况是没有反弹光/全局光照,只有直接光照。
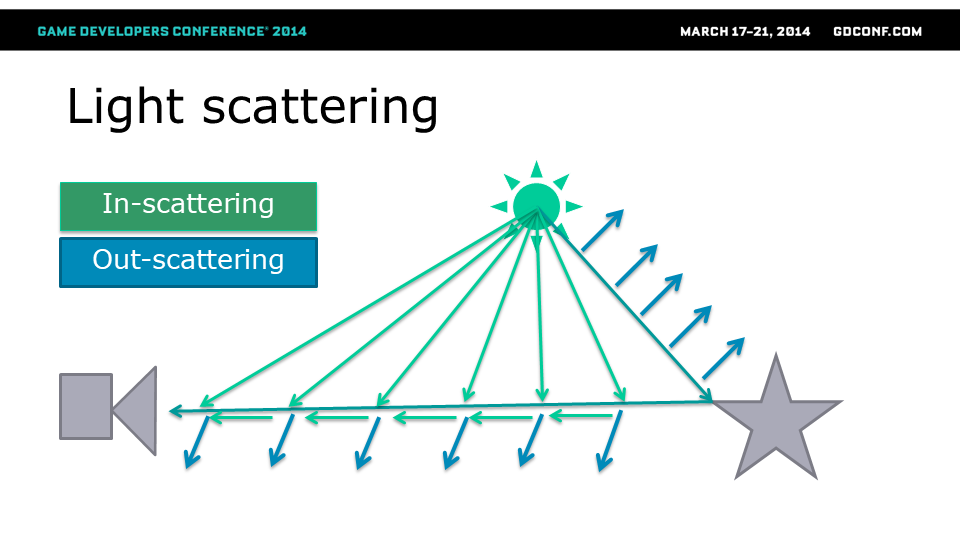
当介质参与光线传输时,每个大到足以影响光子/光线的粒子都会参与光线传输方程。
例如,尘埃或水粒子会使一些光线/光子随机反弹,使部分光线进入光路(内散射inscattering)。与此同时,另一些光线会被反弹出去,离开光路并变暗(外散射outscattering)。
显然,现实中这非常复杂,因为每个粒子都会根据相位函数同时进行外散射和内散射,因此多条光线会多次进出光路。但在实时渲染中,我们通常不得不忽略多次散射。

首先,光线散射效果并非总是清晰可见,多数情况下其实可忽略不计。其可见度取决于以下因素:
- 介质——例如空气/水/蒸汽/牛奶具有不同的介质颗粒尺寸;
- 距离——远山上的光线散射容易观测,而在数米范围内的洁净空气中几乎察觉不到任何效果;
- 光线角度——散射相位函数导致正午天空呈现蓝色,黄昏/黎明时呈现橙粉色;
- 天气条件——不同天气意味着空气中悬浮颗粒的尺寸差异(例如更多尘埃或蒸汽/水珠);
- 光线遮蔽——若光线被遮挡,则无法参与入射散射,这正是形成迷人光柱效应的原理。
其次,该问题极难解决,因为散射方程属于微分方程,其解是一个无法针对”任意”散射介质、遮蔽条件和环境进行解析求解的微积分问题。
因此,游戏开发者长期采用各种低成本近似方案,包括:
- 基于后期处理的”上帝光”
- 基于布告板/粒子系统的光柱
- 基于距离的线性或指数雾效
- 通过光线步进实现的体积阴影
不过这里评估后发现,这些技术均无法满足项目的需求:这里曾对上述所有方案都做了实现,后面法线这些方案都是孤立的技术点,而项目需要的是一个基于物理的统一解决方案——既能整合所有效果,实现视觉一致性,又能让美术同学免于繁琐的设置工作。

===============================================================================================
以下为机翻内容,准确性稍弱,后续等有相关的工作需要再来调整,各位看官先随便看看~
===============================================================================================
在尝试了众多“经典”技术原型后,我们最大的灵感来源于安东·卡普兰扬在2009年Siggraph大会上提出的”光传播体积”全局光照技术。 该技术在总结与未来展望部分提到:利用已光照的体积纹理——即通过光线注入与传播来模拟全局光照的结果——计算参与介质的光线传输。 这种方法的优势在于只需执行一次光线步进,不受光源数量限制,可将参与介质中的整个光线传输过程统一处理。我们意识到,若加入简单的阴影计算项,仅需付出阴影计算的代价就能获得体积光/上帝光效果。 于是我们决定沿着这个方向探索。
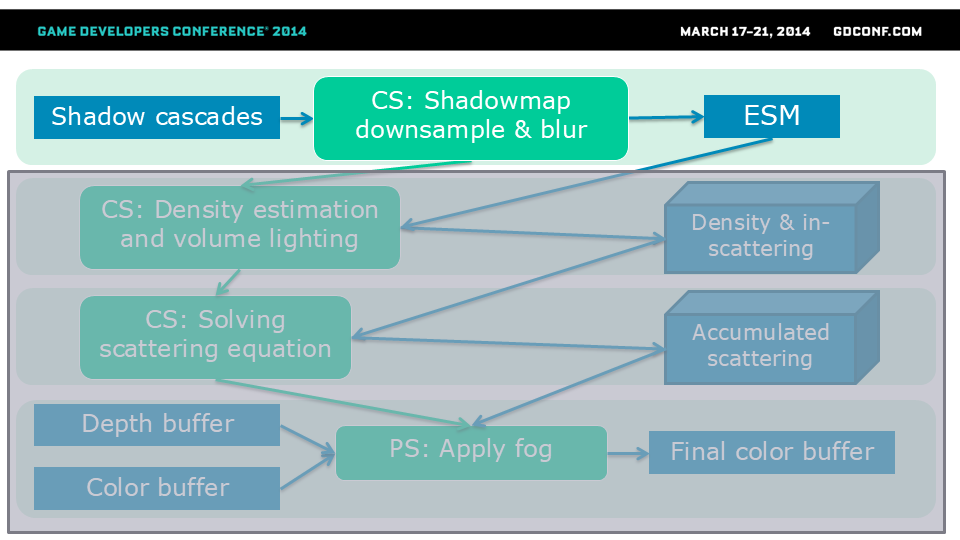
我们的算法包含三个基本步骤(外加一个用于在延迟渲染管线中应用雾效或作为后处理效果的步骤)。我将分别介绍这些步骤。
第一步是准备用于计算阳光散射阴影的雾效所需的阴影贴图。

我们为什么需要它? 我们常规的级联阴影分辨率非常高(4个级联,1k x 1k),其中包含密集的高分辨率信息。 对我们来说细节太多了,尤其是近距离范围和前两个级联,集中在最初的几米内。 为了实现平滑且近似的体积雾效果,我们需要分辨率低得多的东西,以减少移动植被等引起的闪烁/锯齿伪影。 最初使用宽核PCF的实现性能非常差,仍然存在一些闪烁和锯齿伪影。

解决方案源自指数阴影映射算法。 首先,我们将级联阴影贴图下采样四次(目标为R32F格式的1024x256纹理)。在下采样过程中,我们计算指数阴影概率分布(参见《指数阴影映射》,这是对方差阴影映射的扩展,使用指数概率分布函数替代切比雪夫不等式)。 在此过程中,我们还额外进行了可分离的盒式滤波(分为两个独立步骤),以使阴影更柔和并消除锯齿伪影。

解决方案源自指数阴影贴图算法。 首先,我们将级联阴影贴图降采样四次(目标为R32F格式的1024x256纹理)。在降采样过程中,我们计算指数阴影概率分布(参见《指数阴影贴图》,这是对方差阴影贴图的扩展,使用指数概率分布函数替代切比雪夫不等式)。 在此过程中,我们还额外进行了可分离的盒式滤波(分为两个独立步骤),以使阴影更加柔和并消除锯齿伪影。
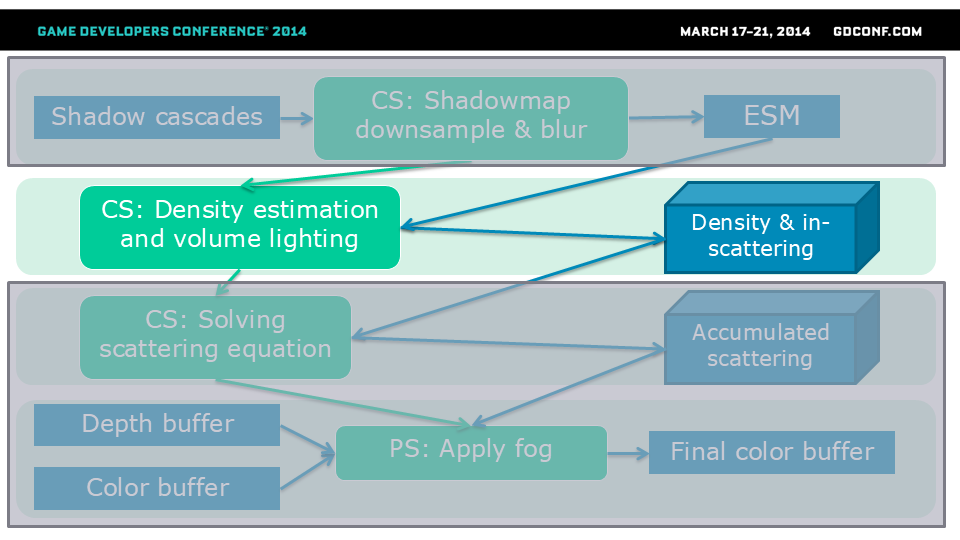
第二步是计算雾密度和散射光,并将其存储到体积纹理中。我们在此步骤使用计算着色器,并为每个体积单元累加被阴影遮挡的阳光、环境光以及与该体积单元相交的多个局部光源的照明结果。为了计算散射光,我们基本上对体积纹理的每个单元执行常规的前向照明。我们还会计算雾密度(这对应于参与散射过程的空气中粒子的数量和大小)。
我们的体积雾效果如何?
最初,我们尝试了最简单的数据布局——与世界空间坐标对齐的长方体。这种布局具有多重优势,例如非常容易实现时间滤波,但通过这种体积进行光线步进需要多次采样,速度较慢且会产生锯齿伪影。
于是我们决定改用与相机视锥体对齐的布局。我们使用宽度x高度轴上的归一化设备坐标直接将视锥体映射到长方体,对于深度切片则采用线性深度。这种方案存在若干缺点,比如容易出现时间性锯齿和闪烁,但光线步进只需对深度切片进行并行扫描即可。
我们尝试了多种深度分布方案,最终选择了靠近相机端更密集的分布——这个区域最需要精度,也最容易出现锯齿伪影。注意:即使采用线性分布的深度切片,实际体积单元也会随着与相机距离增加而变大(由于透视变换),因此要正确计算密度并保持物理准确性,必须考虑这一因素。
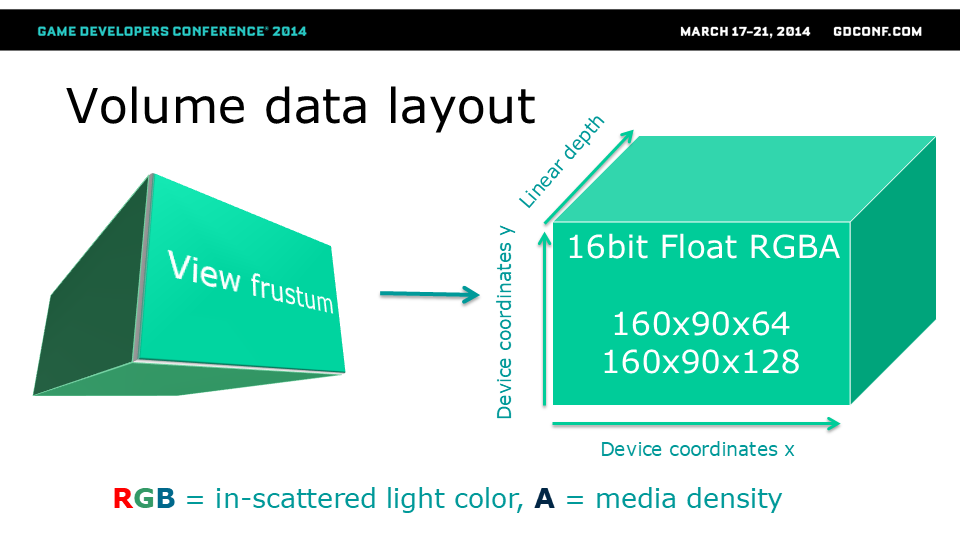
根据平台不同,我们使用160x90x64或160x90x128尺寸的体积。这种设计使得几乎所有处理过程都具有固定成本,不受屏幕分辨率影响。160x90x64布局的纹素数相当于720p画面的纹素数——但每个单元只需执行一次光照计算。
效果范围取决于美术设定的参数,我们将其用于50米以内的距离——以保持远距离雾效与次世代美术风格一致——但这并不妨碍实现更远距离的雾效(通过指数深度分布或级联方法实现)。

我们的体积纹理分辨率看起来可能极低,但已经足够: 我们为光线路径上的每个深度存储低频信息。 每个目标像素都能从其原生分辨率获取准确且精确的深度信息。 由于在应用效果时,我们对体积数据使用了四线性过滤,因此无法看到体积纹理的单个纹素。 透视校正和体积形状确保了信息分布的正确性。
显然,生成的效果非常柔和,缺少高频几何细节,但这符合我们的艺术方向,并且与现实非常相似(因为在真实大气中会发生多重散射效应,使光线的外观变得非常柔和)。

[!] 在算法的首次体积渲染阶段,我们使用计算着色器构建参与介质的光照及其密度。由于可以使用3D纹理UAV(无序访问视图),计算着色器能更轻松地原型化这类效果——我们无需通过几何着色器来定位切片层。
出于略微降低带宽占用的考虑,我们将密度计算与光照计算合并处理,但它们也可以拆分并完全解耦。这种分离方案可实现以下功能:例如让局部体积添加介质密度来模拟烟雾排放,或实现完全由美术控制的雾效布局;另一种可能是对光源进行优化——仅需在体积内部计算光照,而非逐纹素循环计算。
密度计算相当直观:仅使用单八度柏林噪声,并通过风力驱动动画。我们曾尝试使用多八度噪声,但最终发现额外性能开销与视觉效果提升不成正比。同时我们还计算了介质密度的垂直衰减,因为像水蒸气这类重粒子通常倾向于聚集在地平面附近。
[!] 光照部分我们简单累加了主光源(日光/月光)、恒定环境光项,以及多个与视锥体相交且被美术标记为影响大气层的动态点光源。对于主光源的阴影,我们采用了前文提到的指数阴影映射技术。

在AC4中,我们没有采用任何基于物理的相位函数。光照颜色渐变(朝向太阳方向)完全由美术驱动。 我们使用了两种颜色的相位函数——太阳方向与反方向,除此之外采用完全各向同性的形态。 显然,这一阶段可以应用任何相位函数来实现更符合物理规律的效果。
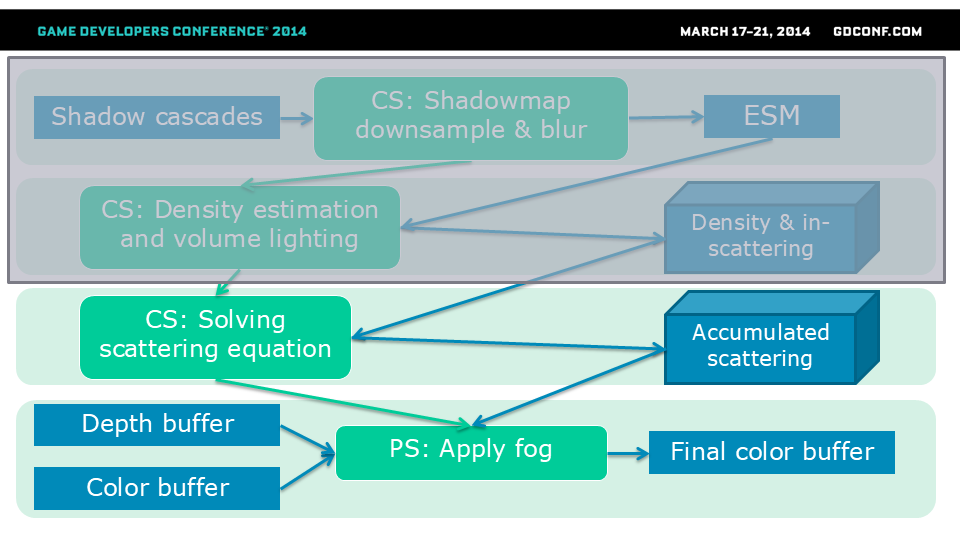
第三步是通过线性遍历雾体积并执行数值微分解来求解散射方程。 第四步是延迟渲染器的典型步骤,即结合来自散射解(仅需一次双线性体积纹理采样!)、深度缓冲区和无雾光照缓冲区的数据。这一步在前向渲染管线中是不需要的。
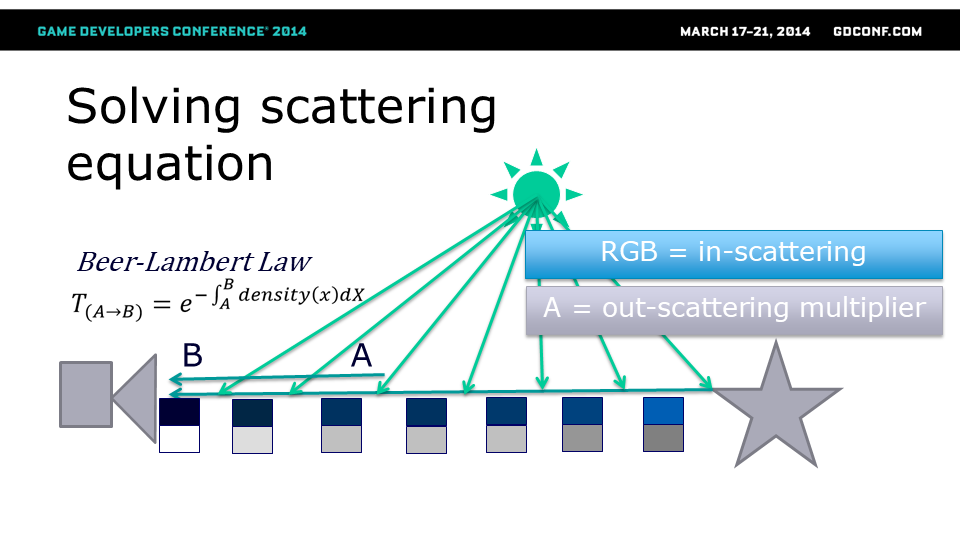
那么,我们该如何求解这个散射方程呢?
外散射效应由比尔-朗伯定律描述,即给定距离下密度积分的指数衰减函数。 对于内散射,则是迄今为止所有内散射光线的简单求和(同时考虑基于距离的外散射)。
我们已经计算并将内散射值累积在体积纹理中。 因此,对于每一条光线,我们可以简单地从相机开始穿过体积,计算密度总和,累积内散射辐射和外散射衰减因子。

我们的计算着色器在每一步都累积了内散射光和雾密度(数值解)。 这样,我们最终会得到一个体积纹理,其中每个纹素都记录了从相机到给定3D点的内散射光量,以及我们累积的参与介质密度(这描述了外散射入射光的量)。
这些数据可以以正向(在绘制物体时直接应用)或延迟(作为全屏四边形通道)的方式使用。

我们的计算着色器在每一步都累积了内散射光和雾密度(数值解)。 这样,我们最终会得到一个体积纹理,其中每个纹素都包含了从相机到给定3D点的内散射光量,以及我们累积的参与介质密度(描述了外散射入射光的量)。
这些数据可以以正向(在绘制物体时直接应用)或延迟(作为全屏四边形通道)的方式使用。
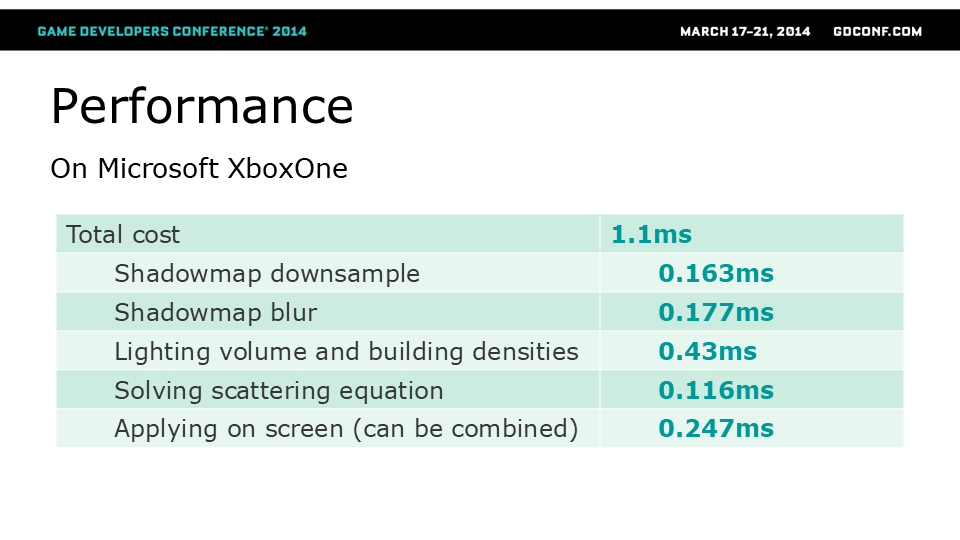
体积雾效果 - 性能表现
总消耗时间出乎意料地低,约为1.1毫秒。以双倍分辨率计算时消耗时间为1.6毫秒。 最耗时的部分是构建密度和体积光照,约0.43毫秒。 其余通道均低于0.2毫秒,除了可与光照合并而”免费”的”应用”通道。 此外,低分辨率ESM对其他低频半透明或透明阴影(如冰等半透明物体或粒子效果)非常有用。


概述
效果兼容延迟渲染与前向渲染——只要阴影贴图可用,甚至可在异步环境下计算(PS4)——不受场景几何结构影响 支持任意数量的透明层或粒子——最终着色器中应用的成本仅为一次tex3D纹理采样+一次线性插值函数! 累积与散射部分的计算成本极低且固定——在720p和4k分辨率下性能消耗相同! 可独立调整密度与光照参数,并支持完全重定义 新增基于物理的相位函数支持 支持多频噪声或美术可控噪声 支持粒子/体积驱动的雾效强度 未来可能支持聚光灯 考虑实现与相位函数预卷积的基于图像照明?

屏幕空间反射技术

这种日益流行的技术(如CryEngine 3引擎、《杀戮地带:暗影坠落》采用)仅利用屏幕空间信息,通过深度缓冲区的光线步进来计算反射信息。我们决定采用该技术来增强现代场景中Abstergo工业公司室内场景的表现力,同时提升雨天湿润表面的视觉效果。
该技术的优势包括: 无需额外反射通道处理 任何3D定向点都可成为反射体(不限于单一反射平面) 几乎不占用CPU资源 支持动态反射体与受反射物体 实现光泽表面与近似反射效果

关闭时效果如上

启用时效果如上:在标记区域中,我们观察到反射模糊程度取决于表面的光滑度/粗糙度,这种效果显著提升了角色和物体在场景中的“扎根感”与构图协调性。

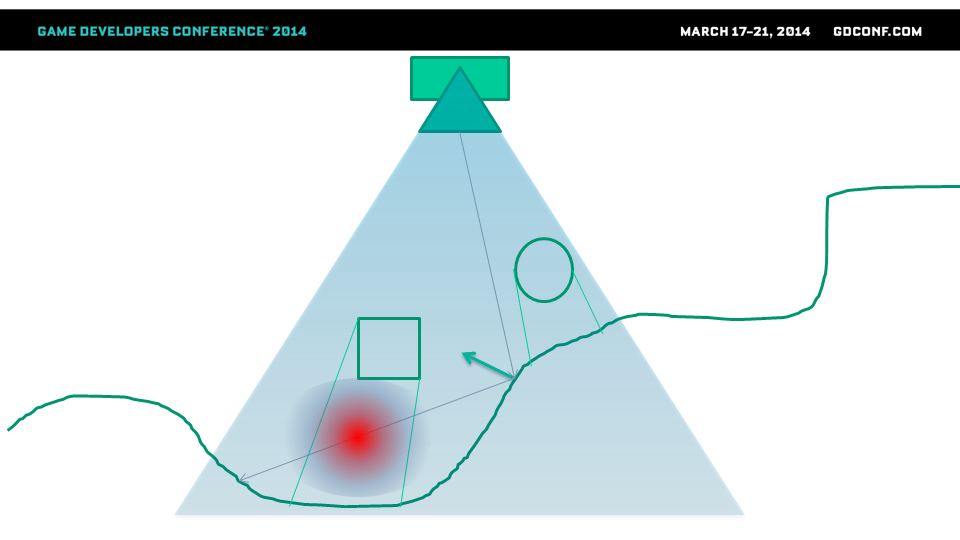
虽然屏幕空间反射在简单情况下效果很好,但当我们的深度缓冲区实际上是一个高度场时,由于缺少物体背后的深度信息,它们就会变得更加棘手——我们必须应用各种启发式方法来确定是否真的存在碰撞。
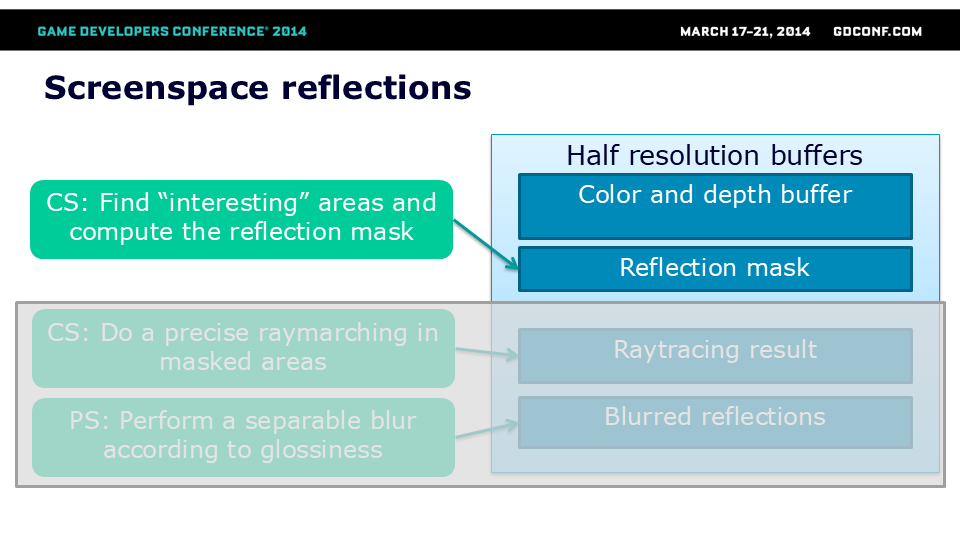
遗憾的是,屏幕空间反射技术在公开可用的资源中并没有很好的文档记录。我们将介绍我们对这一技术的实现,并提及我们是如何随着时间的推移对其进行修改和优化的。
游戏中实现的算法由5个主要步骤组成。我们使用半分辨率的颜色和深度缓冲区作为所有后续处理的输入。

屏幕空间反射只能采样有效的屏幕内信息。通常这类信息量有限,根据场景光泽度和具体情况,实际反射可能占据屏幕尺寸的5%-60%。
此处显示的是潜在反射遮罩——只有这些像素有机会接收某些反射,其余像素要么无法获取足够的屏幕内信息,要么不具备足够高的光泽度/菲涅尔系数使反射可见。
为计算该遮罩并加速后续光线追踪,我们预先计算了这个遮罩。针对每个64x64像素块(来自半分辨率缓冲),我们发射了64条低精度光线。采用预计算的非均匀抖动光线位置分布来最小化走样伪影。这些光线速度极快——采用大步长和超高深度容差(均为最终光线的4倍),仅用于简单判断给定表面是否反射任何屏幕内信息。通过这种方式,后续更精确的通道就无需为那些会反射屏幕外物体的区域和表面启动。我们利用计算着色器的UAV分散写入功能来标记这些区域。
注意每条光线覆盖的影响范围略大于其实际作用区域——这种方式有效降低了遮罩的时间性噪点。
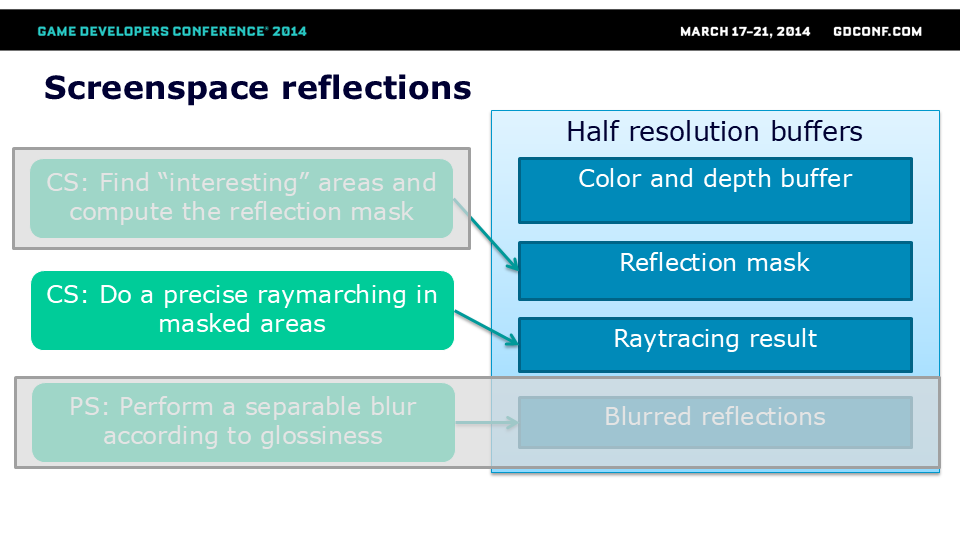
我们利用计算遮罩和计算着色器,通过由深度缓冲定义的深度场进行了最终的高分辨率光线步进。该方法整合了所有可用信息——遮罩、色彩和深度缓冲来计算反射效果。得益于遮罩纹理,我们可以提前剔除无需光线追踪的整个线程组。最终结果噪点较多且锐利,因此需要额外进行模糊处理。
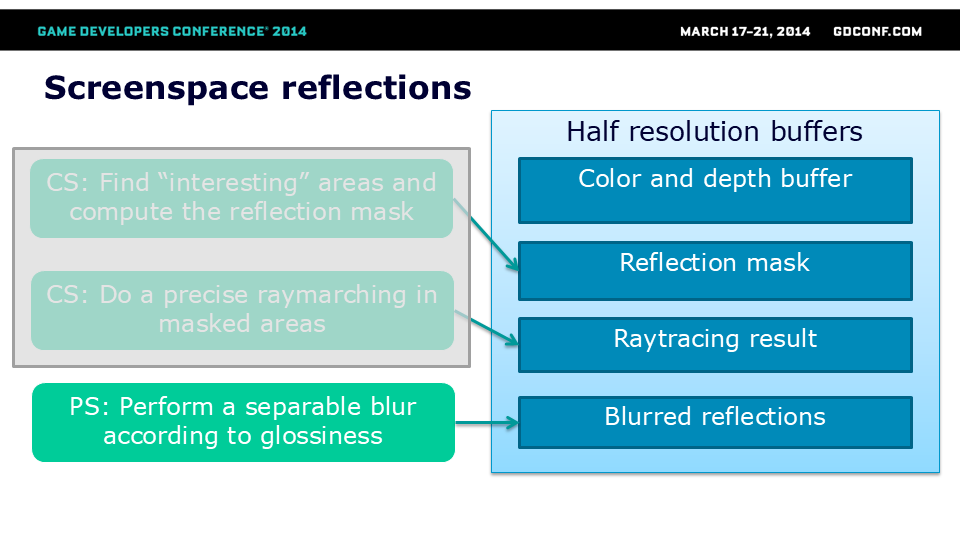
在下一步中,我们使用带有噪点和孔洞的反射遮罩进行了可分离模糊处理。该操作主要实现两个目的:
- 根据光泽度提供差异化模糊效果,以近似模拟非镜面光泽反射
- 降低噪点、消除孔洞闪烁和锯齿现象
模糊半径与光泽度及反射信息可用性成正比——若某采样点属于”孔洞”区域,但根据反射遮罩本应包含反射信息,则会采用更大的模糊/搜索半径。在两次模糊处理过程中,每个采样点的模糊权重还取决于反射信息可用性和光泽相似度(双边滤波原理)——完全不包含反射信息的区域会被大幅降低权重,从而通过这种推拉效应配合光泽模糊实现孔洞填充。

我们在此看到光线追踪后的反射缓冲区示例——它锐利、存在锯齿且闪烁严重,此外由于半分辨率精度不足还包含一些孔洞(用X标记)。 [!] 因此模糊处理实现了两个目的——模糊锐利和锯齿化的反射(箭头标记处),并对孔洞进行推拉式填补(红圈标记处)。 [!] 右侧可见最终效果的近似呈现。这种方式产生了更美观柔和的效果,且在时间和摄像机变化下表现更稳定。
最后,我们利用全分辨率信息对效果进行了上采样。上采样过程较为保守,但并非基于深度——相反,我们排除了反射率不匹配区域的反射,这在本案例中是更优的判定标准(能快速剔除角色及平行于摄像机平面的物体上的反射)。
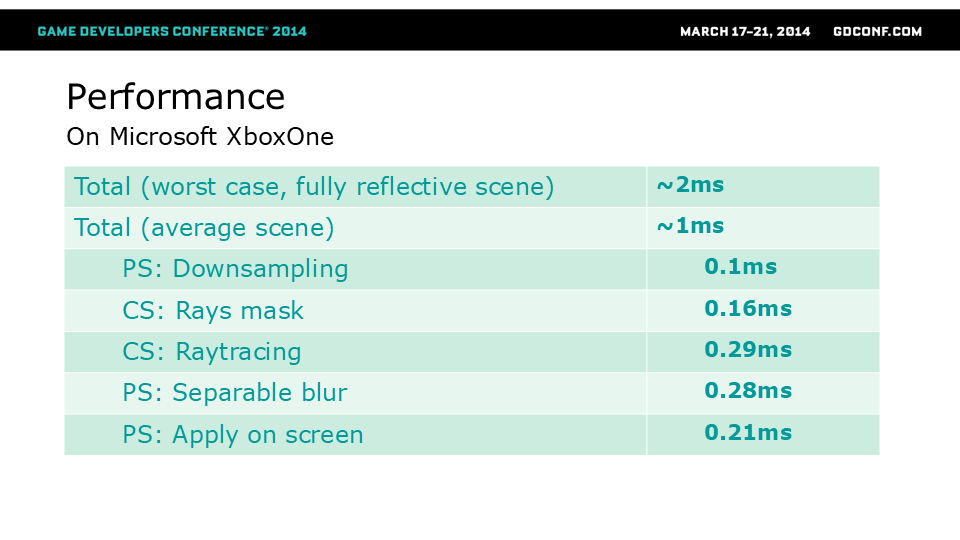
在全反射场景(如我上一张幻灯片截图所示的光滑地板和物体)中,该效果在次世代主机上消耗了我们约2毫秒。 在平均场景(如哈瓦那屏幕上几处水洼)中,耗时约为1毫秒。 PIX捕获分析显示,所有通道的处理时间在0.1毫秒到0.3毫秒之间。



在讨论我们为次世代主机所做的优化之前,我想先谈谈那些改变所有优化方法的重要架构特性和差异。 任何为现世代主机(PS3和X360)做过GPU优化工作的人都知道,这些优化相对简单。
为了优化时序,我们通常只需: [!] 通过改变算法和分辨率(例如在半分辨率下进行模糊处理)来减少整个GPU的工作量。 [!] 减少着色器本身的工作量——通过使用更少的ALU指令、预计算某些数据以及使用查找表来实现。 [!] 通过减少纹理获取(或通过保持采样位置一致性来提高缓存友好性)以及更改资源格式以减少内存占用来降低内存和带宽使用。 [!] 最后,我们可以通过允许适当的指令流水线、重排序和微优化来大幅提升性能(尤其是在PS3上)——某些指令的成本和延迟可以被其他指令完美隐藏。
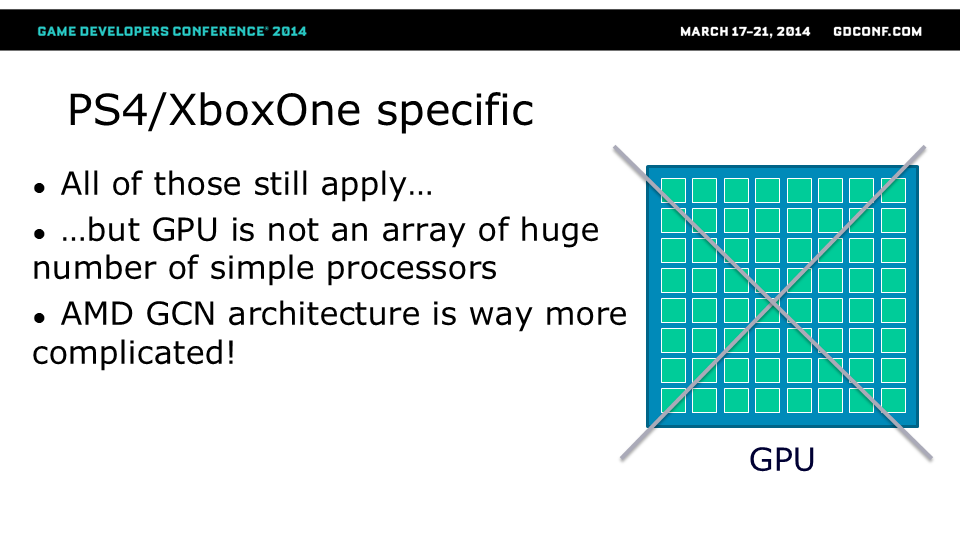
遗憾的是,对于PS4/XboxOne的架构来说,事情并非那么简单。
显然,之前提到的所有优化规则仍然适用。当我们能够将旧款GPU大致建模为大量执行几乎完全相同工作的极简向量处理器时,这些优化手段已经足够。对于上世代主机采用的GPU架构而言,这种简化建模也相当准确。
但不幸的是,这种情况不适用于GCN架构——如今的情况要复杂得多!
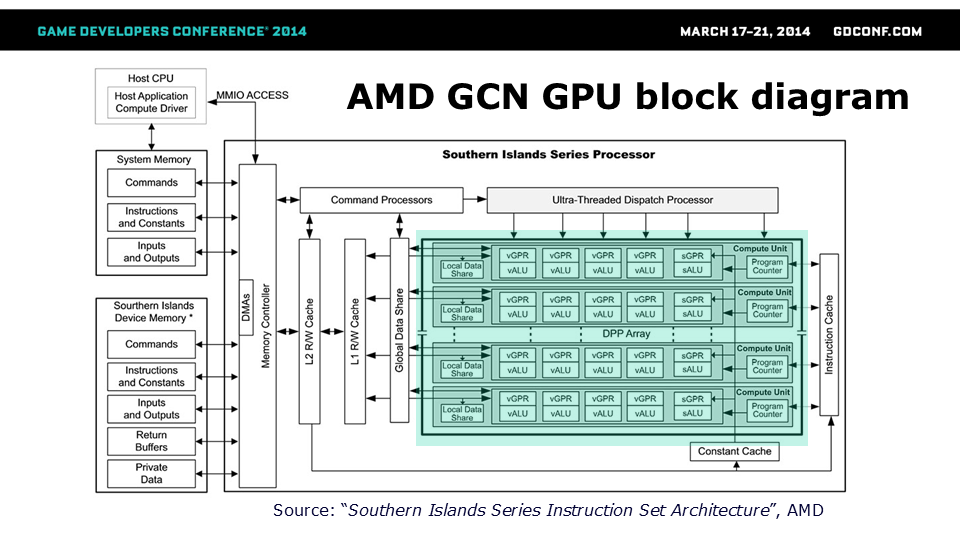
让我们来看看AMD南方群岛GPU,这是GCN GPU架构的典型代表。 除了典型的GPU部件(DMA、缓存、控制器)外,我们可以看到它由多个计算单元(根据文档最多可达32个)组成的“DPP阵列”构建而成[!]。 如此少量的计算单元(32个仅适用于最高性能的GPU,次世代主机配备的更少)以及出色的性能立刻表明,每个计算单元实际上必定是一个相当复杂的处理器。
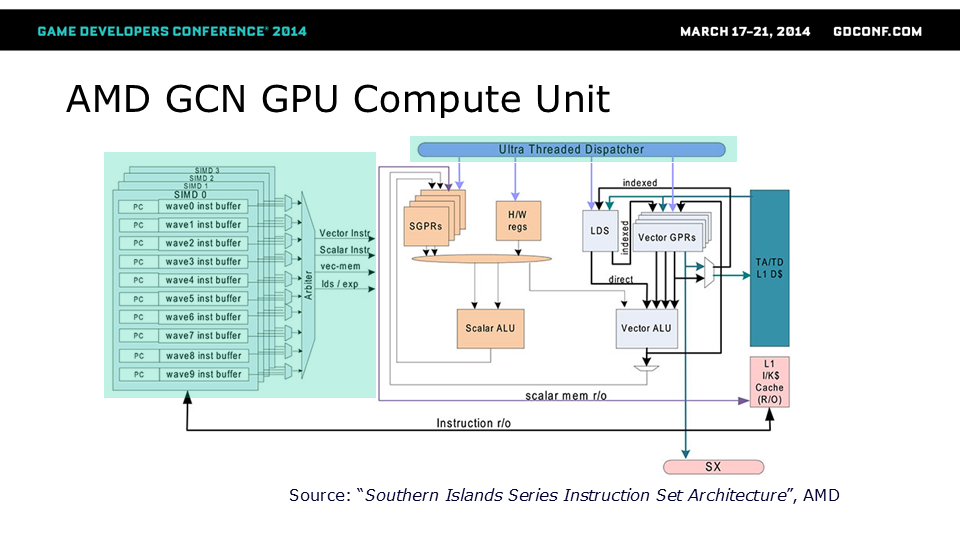
计算单元独立于其他计算单元工作,并与它们并行运行,但它也总是以所谓的“波”形式调度64个“工作项”的并行工作。 这种架构的一个显著不同之处在于,多个波可以同时等待调度,而线程分发器可以并行分发多个波的工作。 每个计算单元都有一个内置的线程分发器和仲裁器,它们可以在每个SIMD上分发多达10个波的工作负载。 让我们看看多个波和4个SIMD通道如何影响性能。



内存操作的延迟可能非常大——在缓存未命中的情况下可达数百个周期。 为了掩盖这种延迟,你需要更高的着色器波占用率和适当的ALU与内存操作比例——这样其他波就可以在此期间执行一些工作。 通过这样的代码修改,我们可以实现多个波的近乎完美的流水线化,以及昂贵内存操作的高度并行化。

内存操作的延迟可能非常高——缓存未命中时可达数百个周期。 为了掩盖这种延迟,你需要更高的着色器波占用率和适当的ALU与内存操作比例——这样其他波就可以在此期间执行一些工作。 通过这样的代码修改,我们可以实现多个波的近乎完美的流水线化,以及昂贵内存操作的高度并行化。
但SIMD最多可以执行10个波,那么真正能调度和等待分派的波数量由什么决定呢? CU上所有活跃的波必须共享各种资源。 因此,提高波占用率的关键因素是限制工作项之间的依赖关系,并减少可用资源的使用。
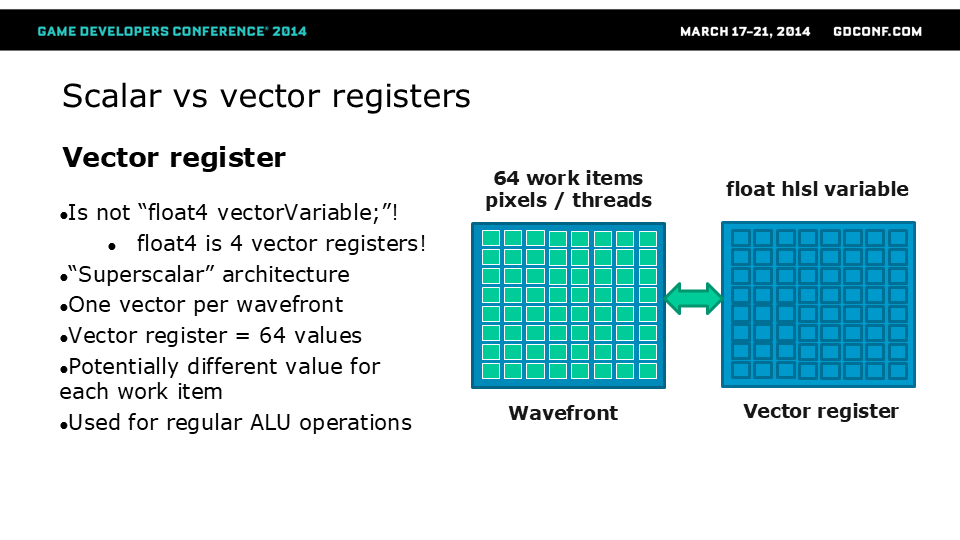
首先,我想谈谈关于标量和向量寄存器的常见误解。

由于波占用率对整个着色器调用的指令缓冲区是全局性的,我们着色器中最糟糕的部分可能会对整个着色器的性能产生毁灭性影响。 从“光线步进代码”的例子中可以看到,像计算光线位置和步长这样的复杂逻辑,会如何影响后续极其简单代码(但可能在大型循环中执行)的性能表现。 因此,与直觉和上一代游戏机开发经验相反,有时拆分渲染通道反而能显著提升性能。

我们习惯于在当代游戏主机(微软Xbox 360和索尼PlayStation 3)上进行编程,但到了采用AMD Southern Islands着色器架构的次世代主机时,一些针对旧平台的常见优化措施反而适得其反,而我们发现其他优化手段更有效:
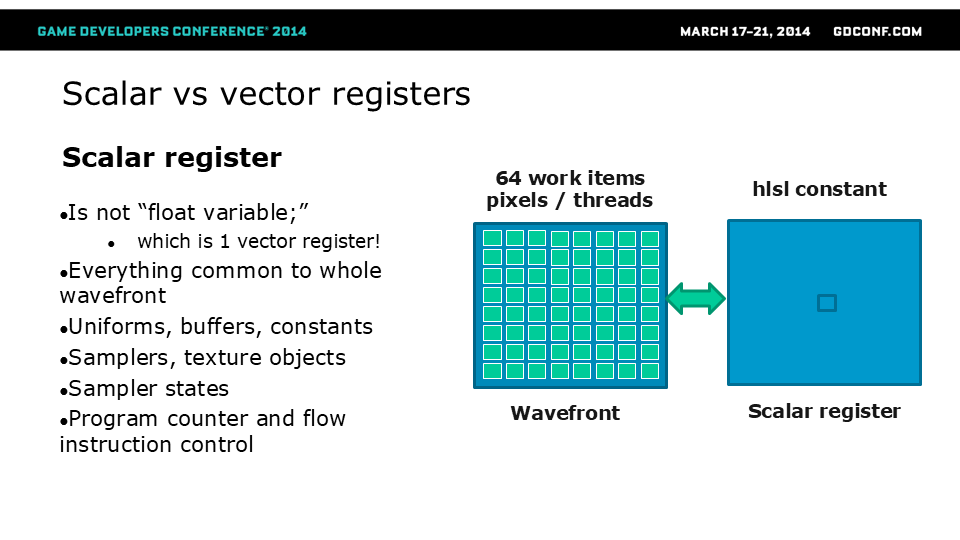
我们发现决定次世代主机性能的关键因素是计算单元着色器波阵面占用率。无论是计算着色器还是像素着色器,在几乎所有案例中都观测到显著的性能差异。波阵面占用率的唯一制约因素是寄存器数量——即便将向量寄存器数量减半也无济于事,如果我们受限于标量寄存器的话。微软为Xbox One开发的PIX工具提供了出色的着色器调试及寄存器使用分析功能。
最简易的降低着色器寄存器占用的方法是缩短临时着色器变量的生命周期。沿用老旧的DX9采样器语义会导致性能欠佳,因为这会引发多重采样器状态获取并占用多个标量寄存器。应当复用采样器状态并尽量减少其数量。这对于从使用传统混合采样器/纹理对象语义的DX9引擎移植的项目尤为棘手,可能严重拖累性能表现。
在采样位置精确已知的情况下(尤其是计算着色器和后期特效处理时),使用Load或operator[]内部函数通常比Sample更高效——前者消耗更少的标量寄存器,能提升波阵面占用率。但需注意从浮点数转换时的半像素偏移和舍入问题!

通常为了节省带宽(尤其是在X360上,“解析”操作的成本不容忽视)并实现更好的像素着色器纹理缓存延迟隐藏,我们会将多个通道合并在一起。使用计算着色器时,这甚至更容易——通过本地内存和线程同步,可以将多个通道批量处理。我们惊讶地发现,这样的尝试往往适得其反。 另一个例子是,将从CS中完成的16次PCF采样改为可分离滤波的ESM,带来了性能和质量的显著提升。 本地数据存储内存非常快速且方便,但过度使用(尤其是在“大”线程组中)往往会破坏并行性。


有时循环和分支比展开循环更好。着色器编译器可能会增加展开循环的寄存器使用量,从而导致性能下降。分支也会增加寄存器使用量,因此应谨慎使用,但如果某个着色器分支意味着无需工作,并且你能提供良好的PS四边形或CS线程组一致性,它们就能有效跳过大量ALU和内存读取操作。
我们发现,部分手动展开循环(例如同时对4个样本进行操作)能带来最佳性能和着色器代码表现。出于某些原因,着色器编译器在处理[unroll]指令时表现不佳…
向量寄存器和指令对float4的单个分量进行操作,因此如果计算中不需要4个分量,就不要使用!这样线程调度器就能在空闲通道上安排其他工作。常见情况是用float4存储颜色——但这并非总是必要的。
这一点相当明显,但在着色器模型4.0-5.0中有大量新指令!如果你刚从PS3/X360转向次世代开发,请查阅文档并找到对你有用的指令。







该技术效果显著,大幅提升了画面质量。但仅使用四个基向量也带来了诸多问题: 低矮环境物体缺乏明显的侧向反弹光; 地面颜色严重渗透到侧面,导致周边物体色调失真; 基向量未正交归一化,导致不同方向上的能量出现损失或增益。我们建议未来项目改用立方体贴图基向量或三阶球谐函数。

我们深知当前技术存在诸多局限——这些局限大多源于对当代与次世代版本美术风格一致性的要求。艺术家和灯光师不愿重复全部工作,而我们则希望避免平台专属的内容错误。
我们曾希望将辐照度存储基准改为更精确、基于物理的方案。采用HL2基准并添加向下”环绕”向量的方案效果欠佳。该基准并非标准正交基,会导致能量增减失衡,并使侧面细节大量丢失。我们尝试过立方体贴图基准(6个基向量),效果显著提升,但因当代/次世代版本兼容性问题或当代平台性能损耗而被迫放弃。结论:建议采用立方体贴图基准或球谐函数基准(三阶球谐可能不适用于PRT存储,但堪称辐照度存储的完美方案)。
我们考虑为反光物体添加间接高光。初期尝试效果喜人,但因当代平台计算成本翻倍而搁置。 提升探针密度。这在次世代平台易如反掌,可实现更高密度的探针布局。还可采用高度轴向多层分布替代高度混合——即使仅设置少数层级,也能完美适配AC关卡布局。 我们本可存储真实HDR辐照度与间接天光照明,而非”标准化”辐照度,但因当代平台内存消耗(多重天气预设)而放弃。 处理多重反射。这项已实现的功能最终因烘焙时间激增和HDR缺失而割爱。 实时更新部分探针(如近距离探针),将计算量分摊至数帧完成。这在次世代主机完全可行(尤其当所有数据存储于GPU时),间接照明还能获取动态物体的阴影信息。


我们尝试了多种屏幕空间反射的实现方案。 最初版本采用分层深度缓冲技术,将深度最小/最大值存储在RG通道中并扩展边界。 这种方法略微优化了光线步进环节(通过加速跳过”无趣”的大片区域),但引入了固定开销——即便屏幕上没有反射像素时仍需承担(游戏中大部分情况如此)。 后来发现,移除该步骤并简化光线步进循环中的mipmap选择逻辑后性能显著提升,部分原因是通用寄存器占用大幅降低且着色器波阵占用率提高。最终版的最内层步进循环极其精简,仅占用少量寄存器。 当然未来还需要进一步实验验证😊
我们曾尝试将遮罩通道与最终光线追踪通道合并,但任何使用LDS标记像素并调用GroupSharedMemoryBarrierWithGroupSync()的方案都会导致严重卡顿——问题可能仍源于波阵调度效率骤降。
光线步进采用两步半分辨率像素步长(约合4个全分辨率像素),在检测到碰撞后通过额外的小步长进行结果优化。这种方式可能会丢失极薄物体的反射效果,但对较大物体而言,性能几乎翻倍且画质无损。

快速证明我们使用的代码确实非常简单。😊

视差遮蔽贴图
我们曾希望提升物体的几何细节,但在公司内部完成了几项曲面细分原型后,发现这意味着完全不同的内容生产流程,会引发几何不连续、平滑组缺失、UV接缝等问题。考虑到只有少数美术师能制作次世代专属内容,我们决定放弃这条技术路线。
我们需要一种能轻松应用于现有本世代资源、提升所有网格类型视觉细节的解决方案——只需更换材质并创建新的高度图纹理。在这些限制条件下,视差遮蔽贴图成为完美选择。
该技术尤其擅长表现分层材质,比如让石头上的苔藓呈现惊艳的立体效果。仅需对单层启用视差遮蔽贴图,就能在没有双网格、贴花或透明混合对象的情况下,营造出层叠的立体视觉效果。
虽然注意到网格转角处和UV接缝存在瑕疵,但最终游戏中因效果微妙而未显现。在攀爬岩壁等场景中,它显著增强了深度感知。经过代码微优化后,暴力计算法表现优异,常规场景中未观测到性能损耗。我们也尝试过Michal Drobot的”四叉树位移贴图”技术,但未见性能差异(可能是波形占用率较低?)

在视差遮蔽贴图(POM)中,与屏幕空间反射类似,暴力线性搜索效果非常好。我们尝试过四叉树位移映射,但由于着色器波占用率大幅降低,其性能和质量结果与前者相近,因此我们保留了更简单、资源依赖性更低的方案。
为了在掠射角度下获得平滑效果,同时避免远距离的锯齿和性能问题,预先计算mip级别并手动随距离淡出效果至关重要。
在PS4上,将最多四次读取批量处理是有益的(参考Guerrilla Games的Valient《杀戮地带:暗影坠落技术复盘》),在此情况下可部分展开循环。
切记关闭高度图及类似纹理的各向异性过滤!在我们的引擎中,资产纹理的过滤设置由美术人员控制,起初他们并未为高度图纹理配置这一选项……
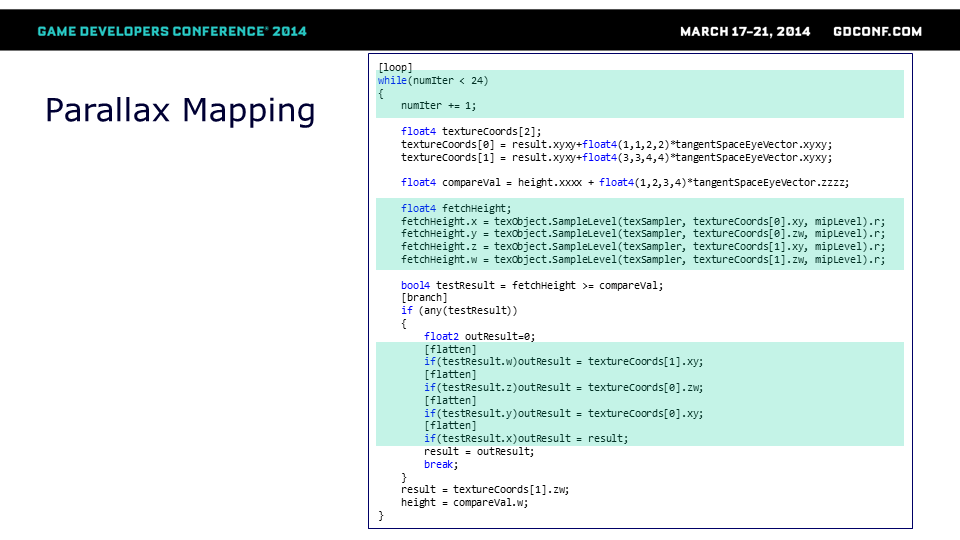
完整的“暴力破解”视差遮蔽映射算法——我们如何批量处理纹理读取。 请注意: 主要针对游戏编辑器添加了安全防护(24次迭代)——以避免在提供错误切线空间的网格等情况时导致驱动程序崩溃。 Mip层级仅计算一次并假定为恒定值 在分支中,坐标以相反顺序进行检查(我们实际上会选择最近的命中点)

雨
加勒比海地区的热带气候极其多变,常有阵雨和暴雨。 我们在之前的《刺客信条》系列游戏中采用了一套不错的天气系统,但这次我们想全面提升雨水和湿润表面的视觉效果。 在新一代主机上,我们计划通过计算着色器和几何着色器来实现这种效果,打造完全程序化生成、但由美术主导的雨景表现。
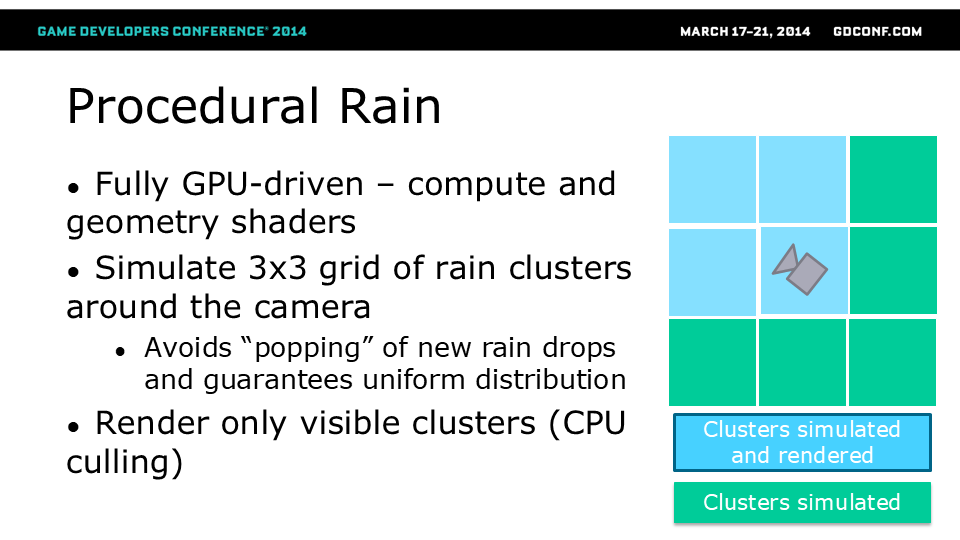
雨滴系统——模拟与渲染 由于雨滴模拟相对简单(但粒子数量庞大),我们决定将整个模拟过程放在GPU上完成。
雨滴的行为和物理特性通过计算着色器进行模拟,随后利用几何着色器将点状粒子扩展为目标雨滴几何形状。
为避免雨滴突然“闪现”的同时保持良好性能,我们设置了9个活跃雨滴簇(3x3网格),以摄像机为中心进行分布。所有雨滴簇都会进行模拟计算,但仅渲染与摄像机视锥体相交的部分。

我们在模拟过程中考虑了多个因素。
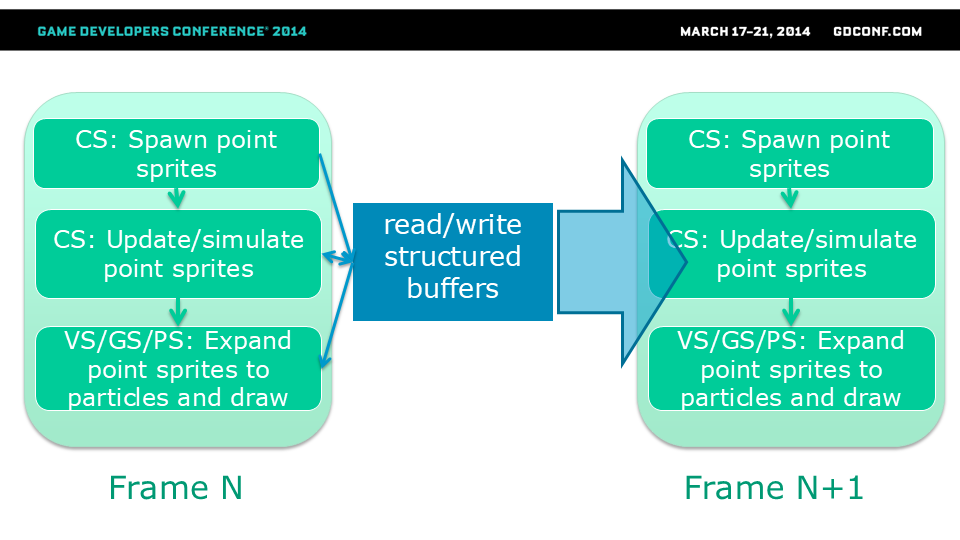
雨水更新流程: 利用雨图作为遮挡信息,我们在每个雨滴簇的随机位置生成新雨滴,并通过计算着色器将其追加到包含历史雨滴的帧缓冲区中。根据雨滴的速度、质量和风力参数更新其运动轨迹,同时通过屏幕空间精确碰撞检测判断哪些雨滴与场景发生碰撞,转而生成溅射效果。每个溅射效果由6个快速消散的宽幅雨滴构成。通过几何着色器将雨滴点扩展为精灵粒子进行渲染。当前帧生成的雨滴精灵粒子缓冲区将用于下一帧的渲染。
第N帧的雨水数据将用于第N+1帧的雨滴系统更新,以此保证模拟效果的连续性。

几何着色器会大幅增加带宽使用——所有生成的数据都必须通过内存传输。 我们发现以下做法很有帮助: 尽量减少几何着色器生成顶点的最大数量和实际数量。 最小化输出和输出顶点的大小。可以安全移除一些冗余字段,并将计算移至像素着色器(PS)。如果这些计算相对简单,它们在逐像素级别上的调度会更高效。有时甚至从全局内存(常量/实例缓冲区)获取这些值效果更好。
在几何着色器中实现某种视锥剔除或遮挡剔除通常很简单。我们发现仅通过这一操作就能让这一阶段的性能提升一倍。 提前退出的分支似乎不会带来明显的性能开销,反而能节省大量生成的带宽。
我们没来得及尝试,但想研究在GPU上生成完整的顶点缓冲区(输出数据量增加4倍——按顶点而非按精灵计算)是否会更好。这可能提供更好的并行性和流水线效率,同时保持完全相同的带宽使用(毕竟这些数据无论如何都必须通过内存传输)。

事实证明,将粒子运动更新转移到GPU是个明智的决定: 计算着色器能在极短时间内处理大量粒子更新。我们甚至更新了不可见的粒子(摄像机后方的粒子群),性能表现依然出色。通过避免多次CPU/GPU同步(如获取雨图、在CPU端生成雨滴飞溅效果、更新动态资源等),我们大幅提升了效率。
虽然计算着色器能实现包含分支判断等复杂逻辑,但某些功能仍需技巧。例如在粒子消亡时生成新粒子,就需要额外增加计算着色器处理阶段。此外,在计算着色器中获取优质随机数也不容易——我们最终采用了预生成随机数缓冲区方案。
将更多粒子系统模拟迁移至GPU以减轻CPU负担的做法绝对值得深入研究。 值得注意的是,我们的计算着色器全程未作任何优化。
几何着色器最终成为性能瓶颈。虽然通过将雨滴模拟为计算着色器中的点数据节省了大量内存带宽,但在几何着色器中将其扩展为实际几何体的过程消耗了巨额GPU时间,迫使我们对其进行深度优化。未经优化的雨效渲染耗时甚至高达20毫秒!


参考
[1]. 【GDC 2014】 Deferred Normalized Irradiance Probes - Assassin’s Creed 4